


組織にいるとしばしば職場の異動を経験します。いわゆる人事異動というものです。私も20年の会社生活の中で幾度となく異動を経験しました。ある意味で異動をしながらキャリアが作られる側面もあります。
その異動の軌跡は、人事システムの中では「異動履歴」という形で記録されています。例えば次ようなイメージです。
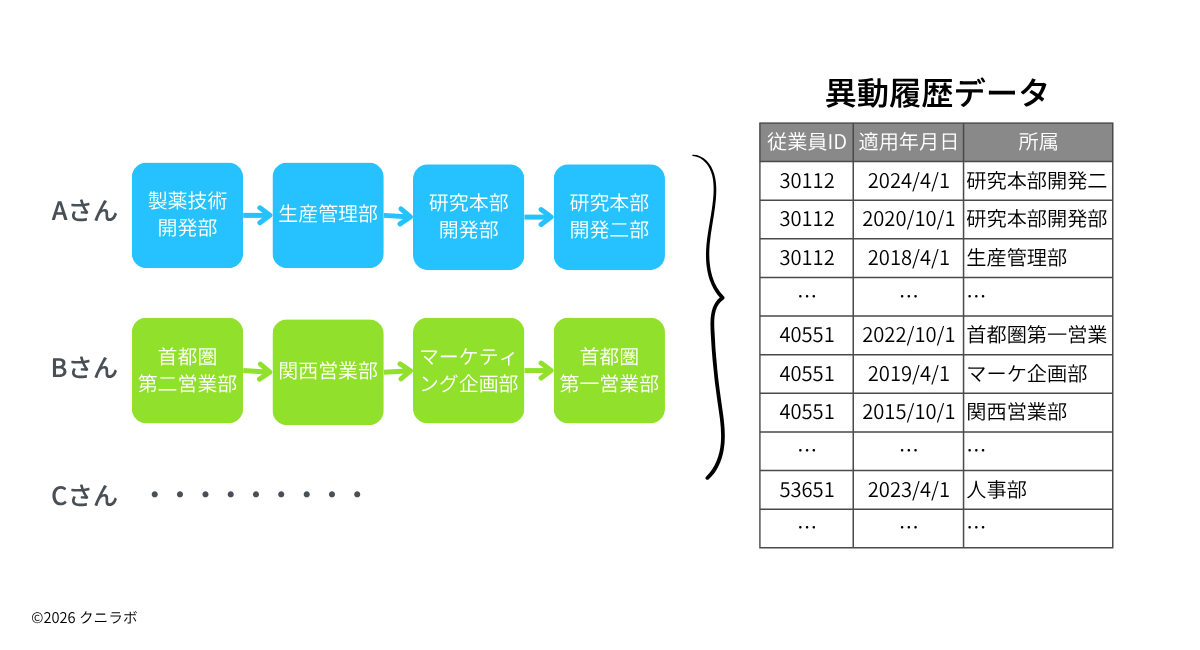
こうした異動履歴データは、人事部門にとって、昇格・昇給管理や次の人事異動案を検討するための重要な情報です。一方で、従業員本人にとっては、自身の職務経験の記録であり、キャリア形成の軌跡そのものでもあります。
そこで、本稿では、異動履歴データを使って従業員のキャリアパスを計量することで、組織内のキャリアパターンを抽出するアプローチをご紹介します。
2026/6/15 追記
本文に入る前に、この記事で取り組んだことを動画にしましたので、ぜひご覧くださいませ。
目次
1 問題設定:社内の異動実態を捉える
ピープルアナリティクスの取り組みの中で「社内にはどのようなキャリアパスが存在するのか知りたい」という相談をいただくことがあります。その目的はさまざまですが、例えば次のようなものです。
- ハイパフォーマーに固有のキャリアパスを見つけたい。
- 従業員が自律的にキャリアを選択できるような情報を提示したい。
- 人事として人事異動がどのように行われているか把握したい。
この中で1と2はイメージしやすいかもしれませんが、3つ目は不思議に思う方もいるかもしれません。「人事であれば、人事異動の実態を把握しているのではないか」という疑問です。確かに、人事部門が中央集権的に異動案を作成している組織であれば、全体像を把握しやすいでしょう。
しかし実際には、事業部門が主導して人材を動かしていたり、一部の経営層がトップダウンで異動を決定していたりするケースも少なくありません。また、ジョブ型人事のもとで社内公募や手挙げ制度によって人が移動する場合も同様です。このような環境では、人事であっても社内全体の人の流れや特徴を体系的に把握することは容易ではありません。
こうした状況のなかで、人事がタレントマネジメントやキャリア開発を考え始めたとき、「社内にはどのようなキャリアパスが存在しているのかを把握したい」というニーズが生まれます。
社内のキャリアパスや異動実態を調べる上で手がかりとなるのが、異動履歴データです。異動履歴データは、多くの人事システムで経年で正確に蓄積されているものであり、人事管理の根幹をなすマスターデータでもあります。従業員ひとり一人について、職場や昇進、職名など様々な人事的な異動情報を記録した重要なものです。
その一方で、異動履歴データは人事のオペレーションを回すために最適な形をしているため、量的に分析しにくいという課題があります。
そこで、本稿では、異動履歴データから組織内従業員のキャリアパスを計量するための「OrgPath2Vec」というアプローチを提案します。これは、これまでに取り組んできたピープルアナリティクスの現場での経験をもとに、私が考案したものです。
それでは、OrgPath2Vecを使ったキャリアパターンの抽出例を見ていきましょう。
2 キャリアパターン抽出例
異動履歴データとして、次のようなデータが手元にあるとしましょう。こちらは、従業員数600名の架空の会社の異動履歴。本検証ために疑似的に作ったもので、HRトイデータとして本サイトで公開しています。
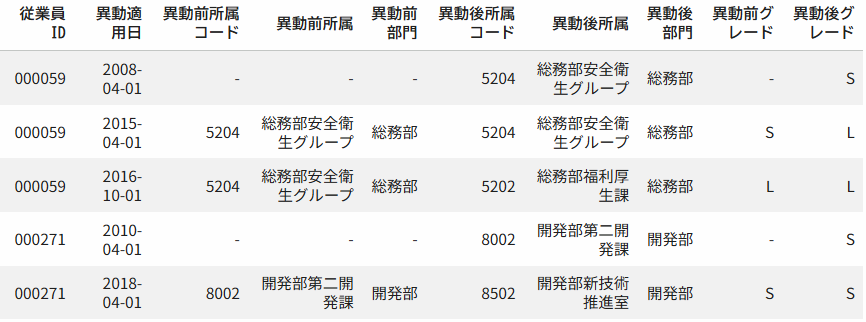
上の例は、従業員IDが000059と000271の異動履歴データを抽出したものです。異動前所属の情報がない(ハイフン)のレコードは初任配置を意味しています。また、データを見ると、職場異動を伴わない昇格の情報も記録されていることがわかります。これが600人分含まれています。
2-1 異動履歴データの設計思想
この異動履歴データは、以下の想定の下でデータを作成しています。こうした特徴を異動履歴データだけで抽出できるのか、というのが今回の問題設定です。
開発部(290名)
- 約8割が開発部内直線型キャリア(4〜6年サイクル)
- 残り約2割のうち、研究部と交流する人材が約65%、全社横断型が約35%
- シニア手前でキャリアラインを外れた人材は品質保証系を経験することがある
営業部(150名)
- 各拠点・課を3年サイクルで回るのが基本
- 全体の約3〜4割が専門室(マーケティング室・商品企画室・新規事業開発室・海外事業開発室)を経験
- まれに20代で開発部へ転換する人材あり
総務部(60名)・経理部(50名)
- コーポレート部門として基本的に部内異動中心
- 50代前後のスタッフ人材が開発部や地方営業へ流出する傾向
- 開発系経験者も在籍
特殊な成り立ちを持つ所属
- 研究部ESG研究課(2015年〜):研究部全体から集約
- 営業部海外事業開発室(2008年〜):営業部全体から集約
- 営業部新規事業開発室(2013年〜):営業部と開発部から集約
- 開発部デジタル推進室(2016年〜):開発部情報システム課から分離独立
- 開発部サービス開発室:開発部と営業部から集約
- 開発部第六開発課(2010年〜)・第七開発課(2020年〜):新設
ランダム異動者(30名、全体の約5%)
- 条件:新卒採用、グレードS/L、成績A/B、エンゲージメント40〜60
- 組織を脈絡なくランダムに異動してきた「優秀だが経歴が読みにくい人材」を模したノイズ設計
2-2 キャリアパターンの抽出
この異動履歴データに対してOrgPath2Vecを利用して従業員のキャリアパスをベクトル化した後、クラスタリングをかけてキャリアパターンを抽出した結果を以下の散布図に示します。
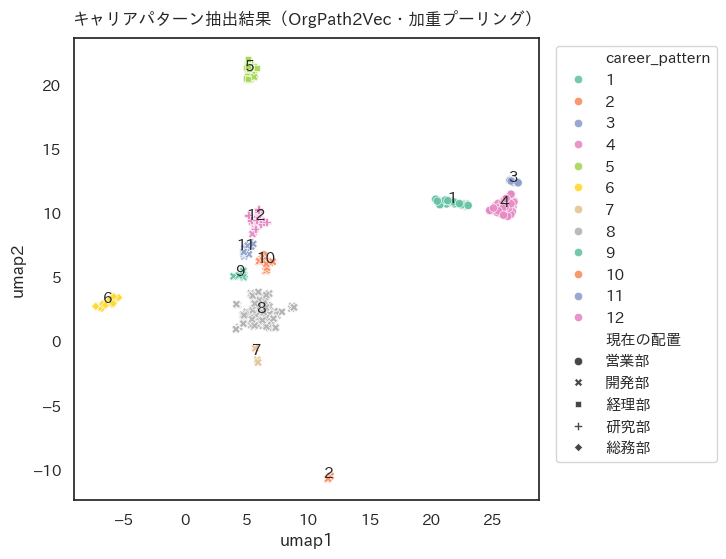
上手では一つの点が一人の従業員を表し、類似のキャリアパスを持つ点が集まるように表現されています。クラスタリングで似たキャリアパスを持つ従業員をまとめると、12個のパターンが見つかりました(点を色分け)。
それぞれのパターンは次ような特徴を持っています。
- 経理部、総務部、研究部はそれぞれ概ね一つのクラスターを形成しており、部門でキャリアを積み上げる傾向があることを示している(5,6,12)。
- 営業部の半数以上が一つのクラスターに集約されており、全国の視点をローテーションしているキャリアが集まっている(4)。ただし、マーケティングや海外事業などにシフトしたキャリアは、その特徴に応じて分離されている(1)。
- 開発部は複雑に分かれている(2,7,8,9,10,11)。特に、新設して人を集めたデジタル推進部門をうまく抽出できている(2)。
これらの特徴は、もともと異動履歴データが持っている特徴と一致しています。OrgPath2Vecを使うことで、データに仕込んだシナリオをおおむねパターン化することができました。
例えば、営業系のキャリアは大きく分けて①ローテーションを続けている従業員と、②キャリアの途中からマーケティングや新規事業に移行している従業員が存在しているのですが、それらを抽出できています。
2-3 キャリアパターンの「典型的なキャリアパス」
12個のキャリアパターンは具体的にどのようなキャリアなのでしょうか。そこで、それぞれのキャリアパターンの典型例を可視化してみました。以下のデモアプリで、C1~C12のボタンをクリックするとそれぞれのキャリアパターンの典型的なキャリアパスを表示します。
この典型例は、各キャリアパターンの平均値にもっとも近い従業員のキャリアを抽出したものです。OrgPath2Vecによりすべての従業員のキャリアパスをベクトル化しているので、こうしたことも容易に行えます。また、各組織の位置関係が2次元空間上に表現されており、組織同士の関係も把握することができます。
2-3 所属コードのみで分析
なお、この一連の分析に使用したデータは、従業員毎の所属コードの履歴のみを使っており、所属名称に含まれる文字情報は一切使っていません。

学習に利用したデータは上の通りで、こうした系列情報のみで人のキャリアパスを計量し、さらに組織のキャリアパターンを抽出できるのは大変便利です。
なお、2-1で示した異動履歴データの設計特性のほとんどを今回のアプローチで抽出することに成功しました。ただし、「ランダム異動者」については切り出すことができませんでした。
3 分析手法
ここからは、実際の分析手法について紹介していきます。
本分析手法は「異動履歴を用いて各従業員のキャリアパスをベクトル化する」というアイデアに基づいています。ベクトル空間上で似たようなキャリアの人は近く、そうでない人は遠く配置できれば、クラスタリングを使って社内のキャリアパターンを抽出できると見込んでのことです。
これを実現するために、自然言語処理の分野で使われているWord2Vecを応用しました。異動履歴を自然言語の文章のように扱い、キャリア(所属コード)の共起パターンを学習することで、従業員一人ひとりのキャリアをベクトル化するというアプローチです。なお、このアプローチはEコマース領域のitem2vecの考え方に着想を得たものです。
そして、従業員の所属経験に応じてベクトルをプーリングすることで、従業員のキャリアをベクトルとして表現します。このプーリングに人事分野の様々な考え方を盛り込むことが可能です。この一連のプロセスをOrgPath2Vec、これにより得られる従業員毎のベクトルをOrgPathベクトルと呼ぶことにします。
全従業員分のOrgPathベクトル(行列)を得ることができれば、そのデータに対してクラスタリングをかけることでキャリアパターンを抽出することができます。
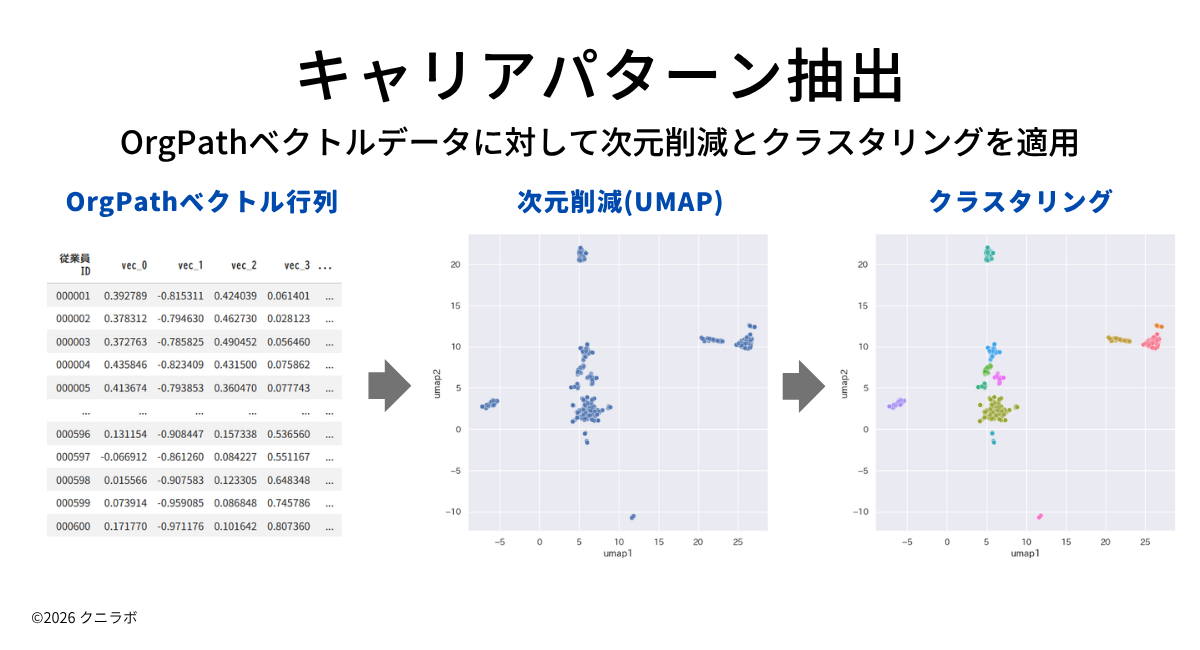
上の抽出例では、UMAPによる次元削減を行った上でHDBSCANを適用した結果を示しました。
4 実装方法
分析に使用したPythonコードを含めて、実装方法を解説していきます。具体的な流れは次の通りです。
- 準備
- OrgPath2Vec(キャリアのベクトル化)
- クラスタリング(パターンの抽出)
- 結果の集約
4-1 準備
分析をはじめる前に必要なライブラリを読み込み、各種設定を行います。
# 基本ライブラリ
import pandas as pd
import numpy as np
from natsort import natsorted
from bidict import bidict
# データ可視化
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
import joypy
# モデリング
from gensim.models import Word2Vec
from umap import UMAP
import hdbscan
from sklearn.metrics import silhouette_score
# グラフの初期設定
sns.set()
japanize_matplotlib.japanize()
# 乱数の設定
SEED = 42
np.random.seed(SEED)続いて、今回分析に利用する人事異動履歴データを読み込みます。
# 異動履歴データの読み込み
th = pd.read_csv('HR-toydata-transfer-history.csv',
dtype={'従業員ID': str, '異動前所属コード': str,
'異動後所属コード': str},
parse_dates=['異動適用日'],
encoding='utf-8-sig')次に、後段のプロセスのために必要なデータ加工を行います。具体的には、データをソートした上で在籍日数を算出します。ただし、各々の従業員は現在の所属に在籍中であるため、最新履歴の在籍日数は打ち切りデータとなっていることに注意してください。
# 昇進のみのレコードを除外し、ソートする
th = (
th.query('異動前所属コード != 異動後所属コード').
sort_values(by=['従業員ID', '異動適用日'])
)
# 在籍日数:次の異動日 - 今の異動日(最終レコードは TODAY まで)
TODAY = pd.to_datetime('2026-04-01')
th['次の異動日'] = th.groupby('従業員ID')['異動適用日'].shift(-1)
th['在籍日数'] = (th['次の異動日'].fillna(TODAY) - th['異動適用日']).dt.daysここで、履歴データにおける在籍期間の分布を確認してみましょう。
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
sns.histplot(th['在籍日数'] / 365, kde=True, bins='rice', ax=ax[0])
ax[0].set_xlabel('在籍年数')
ax[0].set_title('所属在籍年数の分布(全履歴)')
sns.histplot(th.groupby('従業員ID')['在籍日数'].mean() / 365,
kde=True, bins='rice', ax=ax[1])
ax[1].set_xlabel('在籍年数')
ax[1].set_title('従業員一人の平均的な所属滞留年数')
fig.set_tight_layout(True)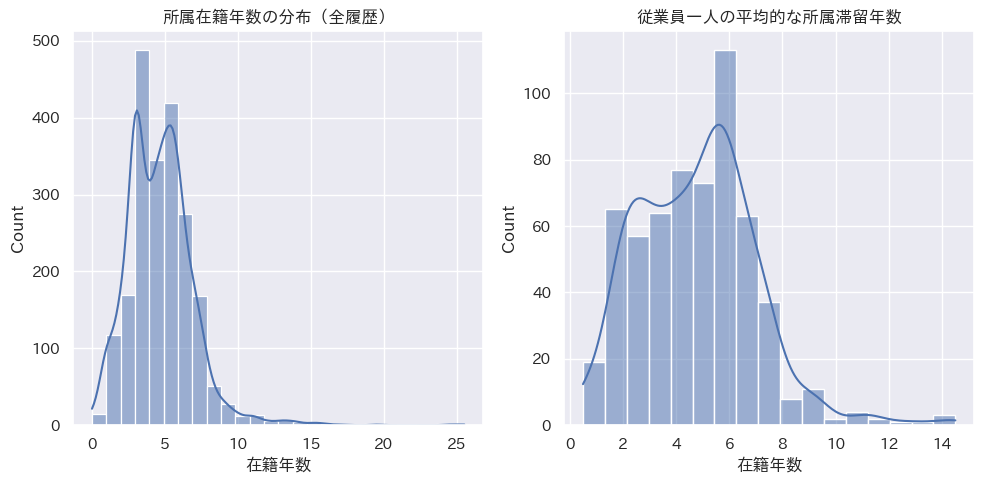
在籍期間が極端に長いレコードもあるようですが、それを除くと概ね5年前後が中心と言えそうです。つまり、平均的にみれば概ね5年で異動しているということです。
また、所属コードと所属名称を変換する辞書を作っておきます。今回は1対1であることが分かっているため、bidictを使って楽をしましたが、本来は片方向ずつの変換辞書を持つべきでしょう。
# 所属コード翻訳用(1:1前提・双方向)
div_map = bidict(
th[['異動後所属コード','異動後所属']]
.drop_duplicates()
.set_index('異動後所属コード')['異動後所属']
.to_dict()
)
# テスト
div_map.inverse['開発部デジタル推進室']'9002'4-2 OrgPath2Vec
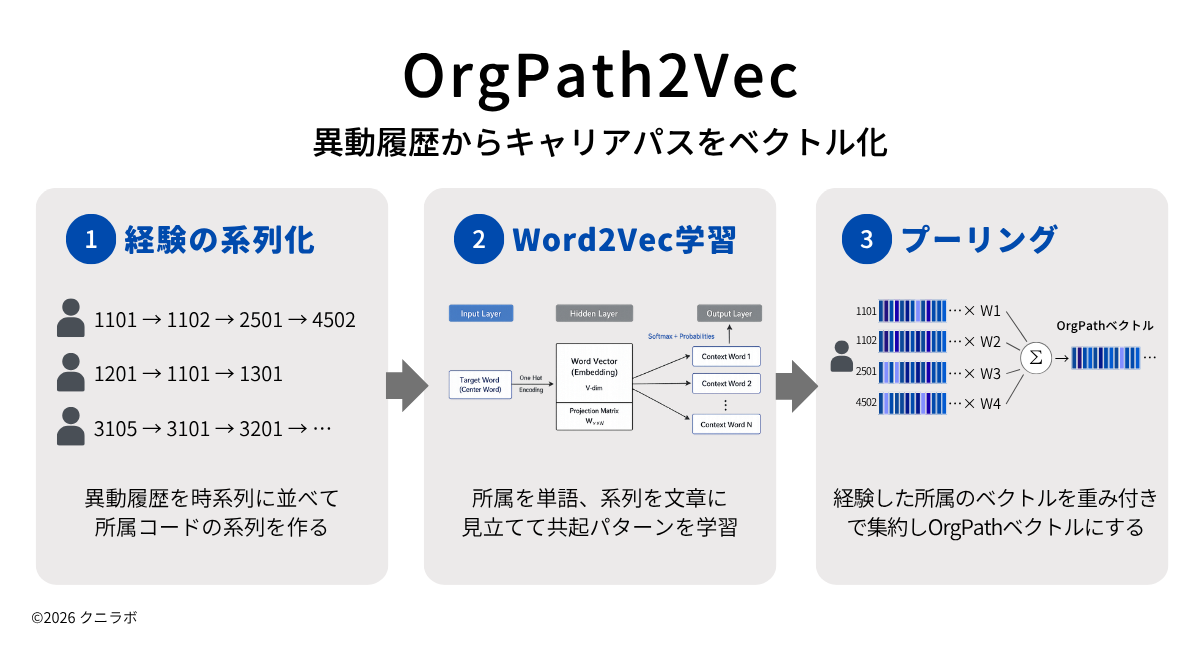
準備が整いましたので、異動履歴データから従業員ひとり一人のキャリアのベクトル化を行います。この一連の処理をOrgPath2Vecと呼んでいます。
1. 経験の系列化(シーケンスを作る)
2. Word2Vec学習(異動系列の共起パターンを学習)
3. プーリング(従業員のキャリアをベクトル化)
それでは順に実装していきます。
経験の系列化
まずはじめに異動履歴データから従業員の所属異動の系列を抽出し、データを構成しとします。これをWord2Vecに投入するシーケンスとします。
# シーケンス(コーパス)の作成
sequences = th.groupby('従業員ID')['異動後所属コード'].agg(list)
print(sequences)従業員ID
000001 [1001, 1101, 1002, 1102, 1103, 1102, 1103, 1001]
000002 [1002, 1103, 1101, 1001, 1002, 1003, 1102, 100...
000003 [1101, 1001, 1003]
000004 [1102, 1101, 1103, 1002, 1101]
000005 [1103, 1003, 1001, 1101, 1003, 1102]
...
000596 [5204, 5201, 1102, 5203, 5201]
000597 [5202, 5204, 5203]
000598 [5301, 5201, 5202]
000599 [5202, 5201]
000600 [5201]
Name: 異動後所属コード, Length: 600, dtype: object上記のように、従業員毎に過去に経験した職場の所属コードが順にリストでまとまる形になっています。これらの所属コードを単語のシーケンスと見立てます。
Word2Vec学習
次に、Word2Vecを用いて所属コードの共起パターンを学習します。直感的には「どの所属とどの所属が同じキャリアに登場するか」を計量します。ここで得られるのは、所属コードの意味的な特徴を示すベクトルです。今回のデータでは40所属に対する32次元のベクトルが得られました。なお、後にUMAPを利用することを想定し、ベクトルの次元を大きめの数字にとりました。
model = Word2Vec(
sentences=sequences.tolist(),
vector_size=32,
window=2,
min_count=1,
sg=1,
epochs=300,
seed=SEED,
workers=1,
)この時点で異動配置という側面から特徴付けられた所属ベクトルが得られており、組織間の類似性を測れる状態になりました。試しに、「開発部デジタル推進室」のベクトルを見てみましょう。
c = div_map.inverse['開発部デジタル推進室']
print(f'所属コード: {c}')
print(model.wv[c])所属コード: 9002
[ 0.12353737 -0.17386287 0.83167684 -0.0762415 0.68148714 -0.35622844
0.5689526 0.03320074 -0.12185653 0.23113619 -0.39845073 0.9235906
-0.3342355 0.11470932 0.54617226 0.86788636 0.77966386 0.46682882
0.22283256 -0.24608748 -0.13047078 -0.9697746 -0.73981816 -0.9202872
0.37263426 -0.06765223 0.7680799 0.40107042 0.26781344 0.84974515
0.4071947 -0.03835464]このように、異動履歴を通した所属の特徴が32次元のベクトルで表現されています。では、この情報を使って、似ている所属を探してみましょう。
print(f'{div_map[c]}と近い所属')
sm = pd.DataFrame(model.wv.most_similar(c), # 類似ベクトルを探す
columns=['所属コード', '類似度'])
sm['所属'] = sm['所属コード'].map(div_map)
print(sm)開発部デジタル推進室と近い所属
所属コード 類似度 所属
0 8007 0.753632 開発部第七開発課
1 8101 0.642873 開発部基盤開発課
2 8006 0.595843 開発部第六開発課
3 8001 0.594155 開発部第一開発課
4 8502 0.585591 開発部新技術推進室
5 8501 0.585099 開発部サービス開発室
6 8005 0.581365 開発部第五開発課
7 8002 0.570143 開発部第二開発課
8 8003 0.531184 開発部第三開発課
9 8201 0.511871 開発部保守グループ実は、デジタル推進室は「開発部の幅広い組織から人を集めて作られた」というデータ設計意図を持っていました。それをうまく読み取れているようですね。
プーリング
最後に、従業員が経験した職場の所属ベクトルを集約します。この集約の考え方に人事の様々な知見を盛り込むことができます。ここでは、シンプルに平均を取る方法と、職場での在籍期間を加味する方法を紹介します。
平均プーリング:所属ベクトルの算出平均をとる。すべての経験を等しく加味する。
加重プーリング: 職場に在籍した期間の長さに応じて重みづけして集約する。経験の長さを加味できる。
まずは、平均プーリングのコードを示します。とてもシンプルです。
# 平均プーリング
vec_df_mean = (
sequences
.apply(lambda seq: np.mean(model.wv[seq], axis=0))
.apply(pd.Series)
)一方、加重プーリングは、在籍期間に応じて0~1の間の重みを付けます。ここでは、ロジスティック関数を用いて1年で3割、2年で8割、3年でほぼ飽和するような重み付けを行いました。図にすると以下のような形になります。
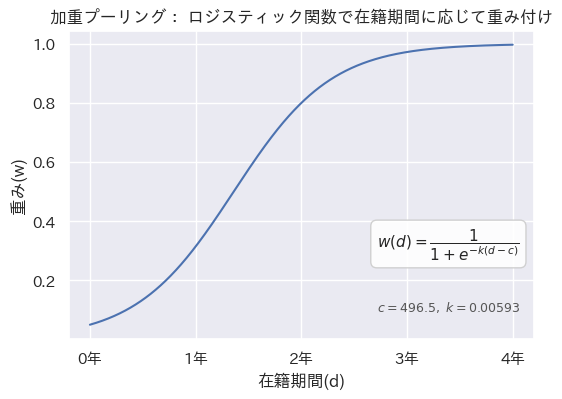
この設定は、メンバーシップ型の組織を想定したもので、一つの職場で3年程度の時間をかけて固有の経験を習得するという仮説によるものです。ロジスティック関数のパラメータ変えることで柔軟に変化させることができます。今回は固定値にしましたが、年代や職種によって可変にしても面白いかもしれません。
重み付けをするコードは次の通りです。
# 加重プーリング(ロジスティック関数を利用)
# 配属当初の重みを抑えつつ、在籍年数に応じて段階的に重みを積み上げる設計。
# パラメータ:1年 ≒ 0.3、2年 ≒ 0.8、3年 ≒ 1.0
CENTER = 496.5
K = 0.00593
def logistic_weight(days):
return 1 / (1 + np.exp(-K * (days - CENTER)))
sequences_with_days = (
th.groupby('従業員ID')
.apply(lambda g: list(zip(g['異動後所属コード'], g['在籍日数'])))
)
vec_df_logistic = (
sequences_with_days
.apply(lambda seq: np.average(
model.wv[[tok for tok, _ in seq]],
axis=0,
weights=logistic_weight(np.array([d for _, d in seq]))
))
.apply(pd.Series)
)これらの処理により、従業員毎のキャリアパスをベクトル化することができました。このベクトルをOrgPathベクトルと呼ぶことにします。また、全従業員のOrgPathベクトルを縦に並べたデータを、OrgPathベクトル行列と呼ぶことにします。
vec_df_logistic.head()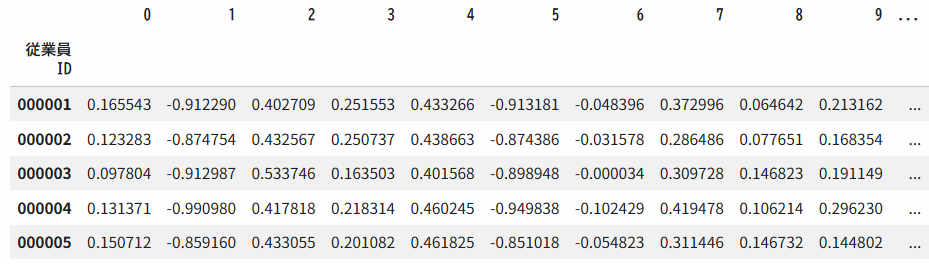
この行列を利用することで、従業員間の類似度計算やクラスタリング、UMAPによる可視化などを行うことができます。
4-3 クラスタリングパターンの抽出
OrgPathベクトル行列ができたら、クラスタリングをかけてキャリアパターンを抽出します。ただし、手持ちのデータでは、クラスタリングをかける前にUMAPで次元削減をした方が良い結果を得ることができました。順に解説していきます。
UMAPによる次元削減
高速かつ高精度に次元を削減できるUMAPを用いて、OrgPathベクトル行列を2次元に落とし込みます。これにより、2次元空間上に似たキャリアパスを持つ従業員が配置されます。UMAPは可視化のために利用されることが多い手法ですが、クラスタリングの前処理でもしばしばワークします。
また、最終的にキャリアパターンを考察する上でも便利です。
# 加重プーリングの場合
emb_logistic = UMAP(
n_components=2, n_neighbors=15, min_dist=0.1,
metric='cosine', random_state=SEED, n_epochs=1000
).fit_transform(vec_df_logistic.values)加重プーリングのデータに対してUMAPで次元削減し、その結果をデータを可視化した例を以下に示します。クラスターを形成していることがわかりますね。
fig, ax = plt.subplots(figsize=(7, 7))
sns.scatterplot(
pd.DataFrame(emb_logistic, columns=['umap1', 'umap2']),
x='umap1', y='umap2', alpha=.6, ax=ax)
ax.set_title('UMAPによる次元削減後のデータ')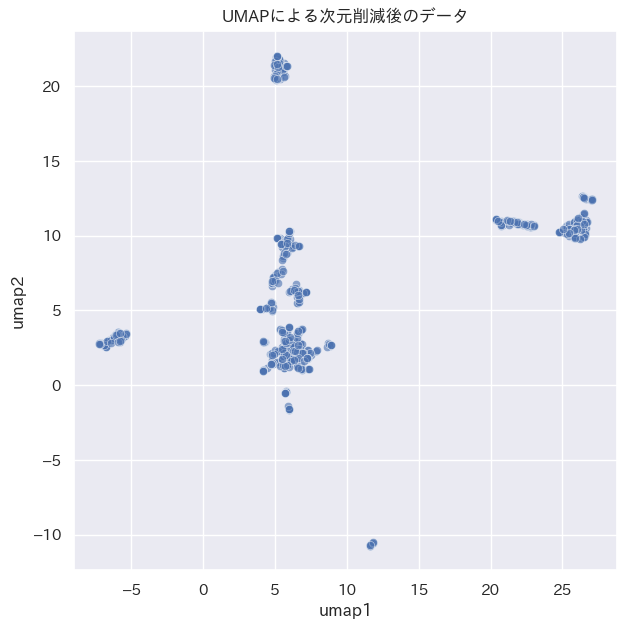
HDBSCANによるパターン抽出
UMAPの出力結果に対してクラスタリングをかけます。具体的な手法としてk-meansやHDBSCANなどが利用できます。HDBSCANは密度ベースのクラスタリング手法であり、クラスタ数の設定しなくてもよいので大変便利です。今回利用したデータでは、HDBSCANの方がデータの特徴を捉えていました。
HDBSCANの実装例を以下に示します。なお、ハイパーパラメータについては、シルエットスコアと外れ値(ノイズ)の検出数、可視化結果を加味して調整した結果を設定しています。
def run_hdbscan(emb, min_cluster_size=13, min_samples=5):
labs = hdbscan.HDBSCAN(
min_cluster_size=min_cluster_size,
min_samples=min_samples,
cluster_selection_method='eom'
).fit_predict(emb)
return labs
labs_logistic = run_hdbscan(emb_logistic)クラスタリングにより、平均プーリングでは11、加重プーリングでは12個のクラスターを抽出することができました。先ほどの散布図をクラスターで色分けすると次のようになります。
d_ = pd.DataFrame(emb_logistic, columns=['umap1', 'umap2'])
d_['career_pattern'] = labs_logistic.astype(str)
fig, ax = plt.subplots(figsize=(7, 7))
sns.scatterplot(d_, x='umap1', y='umap2', hue='career_pattern', alpha=.6, ax=ax, legend=False)
ax.set_title('クラスタリングの結果(加重プーリング)')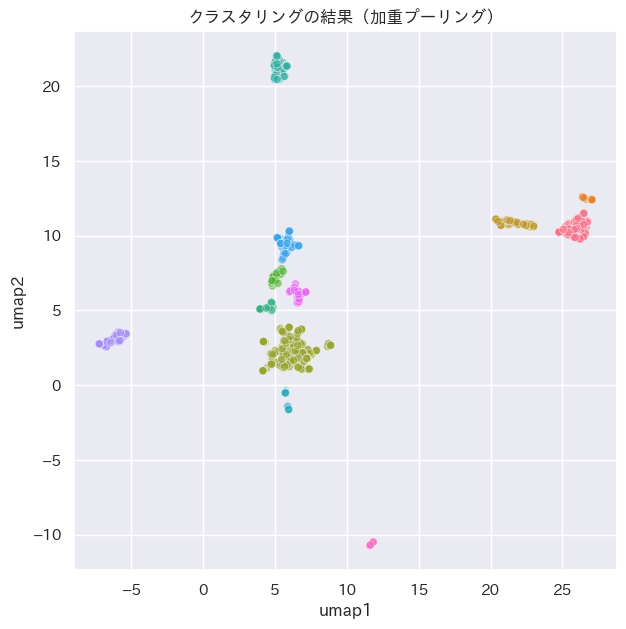
データの集積状況に応じてクラスターを分離できていることが分かります。
4-4 結果の集約
ここまでの処理で得られたOrgPathベクトル行列、UMAPによる次元削減行列、クラスター番号の情報を束ねて考察できるようにします。加えて、人事基本情報を読み込み、現在の配置や人事属性と突き合わせられるようにしておきましょう。
# 人事基本情報の読み込みと結合
hr = pd.read_csv('HR-toydata-basic-600.csv',
dtype={'従業員ID': str, '所属コード': str}, encoding='utf-8-sig')
def make_res_df(emb, labs, vec_df):
raw = np.where(labs == -1, 'noise', (labs + 1).astype(str))
uc = natsorted(np.unique(raw))
return (
pd.DataFrame({
'umap1': emb[:, 0],
'umap2': emb[:, 1],
'career_pattern': pd.Categorical(raw, categories=uc, ordered=False),
}, index=vec_df.index
)
.join(vec_df.add_prefix('vec_'))
.join(hr.set_index('従業員ID'), how='left')
)
# res_mean = make_res_df(emb_mean, labs_mean, vec_df_mean)
res_logistic = make_res_df(emb_logistic, labs_logistic, vec_df_logistic)結合したデータフレームからランダムに1件抽出してみると、ここまでの処理の結果と人事基本情報等が結合されているのが分かります。
sample = res_logistic.sample()
sample
ただし、列が多いのでこのままでは読みにくいですね。表示を工夫してみましょう。以下、Jupyter notebook上でデータフレームの出力を4段組みで出力したものです。
# データのサンプルを4段組みで表示(1行データsampleをターゲットに)
from IPython.display import display_html
indexes = np.array_split(range(len(sample.T)), 4)
dfs = [sample.T.iloc[idx] for idx in indexes]
html_parts = ''.join(
f'<div>{df.to_html()}</div>'
for df in dfs
)
html_str = f"""
<div style="display: flex; gap: 40px;">
{html_parts}
</div>
"""
display_html(html_str, raw=True)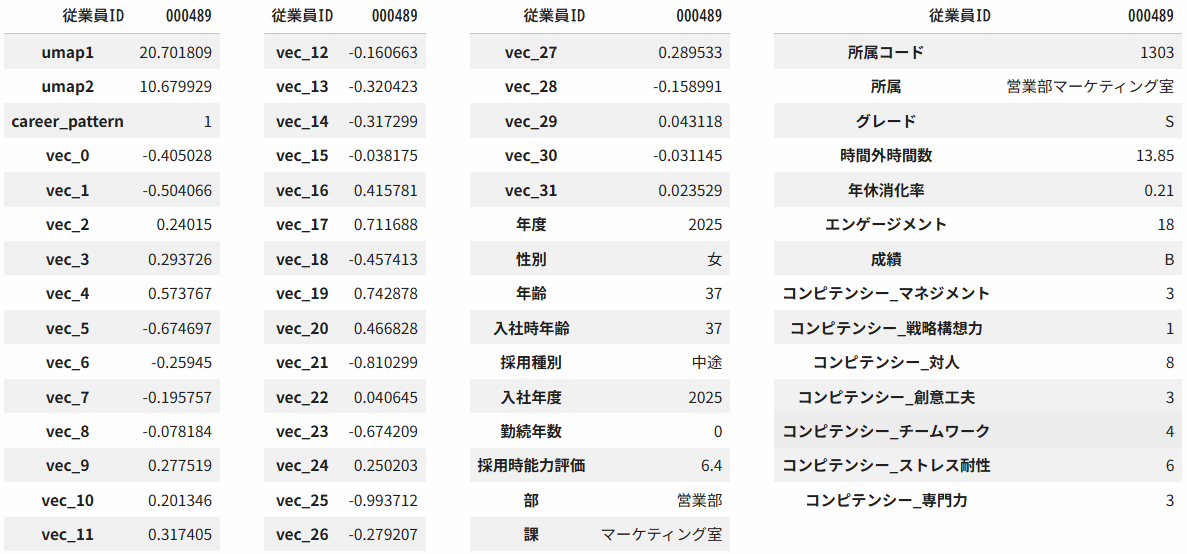
このサンプルを詳しく見ると、2019年に中途で入社した女性で、現在は総務部給与課に配属されているようです。そして、キャリアパターンとして6番に分類されていることが見て取れます。
5 分析結果の考察
キャリアパターンを分析するための情報が出そろいましたので、早速分析していきましょう。以下、加重プーリング版に絞ってみていきます。
5-1 現在の配置から見た考察
まずは、UMAPの出力値を軸に取った散布図に対して、クラスター番号で色分け、現在の配属で点の形を変えてみましょう。これにより、今の組織において、どの様なキャリアパターンが存在するのかをざっくり見ることができす。
# 各クラスターの中心座標とラベルの情報を集約(準備)
clinfo = res_logistic.groupby(
'career_pattern',as_index=False, observed=False
)[['umap1', 'umap2']].mean()
clinfo['label'] = clinfo['career_pattern'].astype(str).replace('noise', '')# 散布図を描く
with sns.axes_style('white'):
japanize_matplotlib.japanize()
fig, ax = plt.subplots(figsize=(6, 6))
sns.scatterplot(res_logistic.rename(columns={'部': '現在の配置'}),
x='umap1', y='umap2',
hue='career_pattern', style='現在の配置',
alpha=0.9, palette='Set2')
ax.legend(bbox_to_anchor=(1.02, 1), loc='upper left')
ax.set_title('キャリアパターン抽出結果(OrgPath2Vec・加重プーリング)', fontsize=12, pad=10)
# 各クラスターの中心にラベルをアノテーション
for _, row in clinfo.iterrows():
ax.annotate(row['label'],
(row['umap1'], row['umap2']), fontsize=11, ha='center')図を見ると、部によって一つのキャリアパターンに集約しているケースと、そうでないケースがあることが見て取れます。より詳しく見るため、現在の配置(部)の構成員がどのキャリアパターンを持っているかクロス集計してみました。
pd.crosstab(
res_logistic['部'],
res_logistic['career_pattern']
).rename_axis('現在の配置')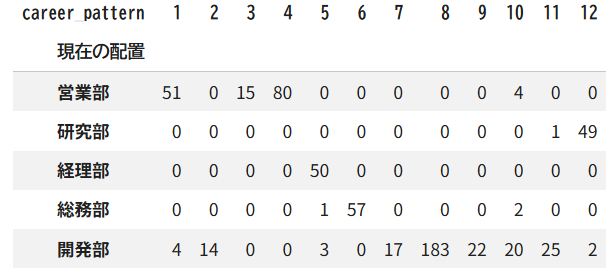
クロス集計の結果を見ると、研究部・経理部・総務部は概ね一つのキャリアパターンに収束しています。一方、営業部や開発部は複数のキャリアパターンがあるように見えますね。
5-2 人事属性による考察
次に、基本的な人事属性を使ってキャリアパターンの特徴を観察してみましょう。まずは、リッジラインプロットを利用してキャリパターン毎の勤続年数の分布を確認してみました。リッジラインプロットはKDEプロットをオーバーラップさせながら可視化する手法で、比較したいカテゴリが多いときに便利です。
fig, ax = joypy.joyplot(
res_logistic,
by='career_pattern', column='勤続年数', alpha=.8, ylim='own',
overlap=1, linecolor='w', title='キャリアパターン別勤続年数分布',
figsize=(6,6), background='w')
ax[6].set_ylabel('career_pattern')
ax[-1].set_xlabel('勤続年数')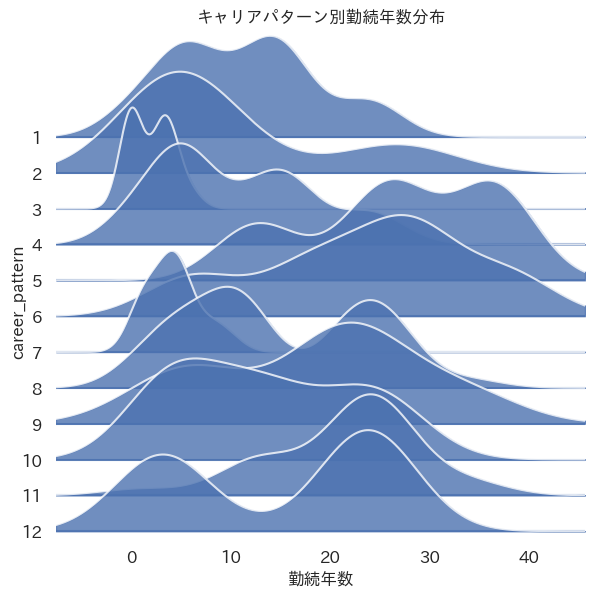
上の図を見ると、キャリアパターンによって随分と勤続年数が異なることが見て取れます。特に、3と7は極端に勤続年数が小さく入社したて従業員で構成されていると想定されます。前節の分析結果から3は営業部、7は開発部のキャリアの一つであることが分かっています。営業部・開発部共に複数のキャリアパターンがあるのですが、それらに分岐する前のキャリアと考えることもできます。
続いて、キャリアパターンの中途比率を見てみました。このデータは新卒の方が多いデータとなっていますが、キャリアパターンによって差があることが見て取れます。
tmp_mat =pd.crosstab(
res_logistic['career_pattern'],
res_logistic['採用種別'],
normalize='index'
).sort_values('中途')
my_colors = plt.cm.get_cmap('Set2').colors[:2]
tmp_mat.plot.barh(
stacked=True, width=0.8, color=my_colors, alpha=0.7,
title='キャリアパターン別中途採用比率')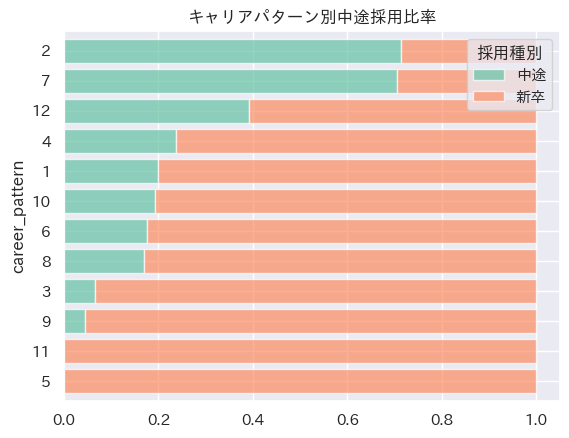
では、勤続年数と採用種別の組み合わせで見るとどうでしょうか。勤続年数のリッジラインプロットを採用種別で分割してみるとわかりやすいはずですが、Pythonでは少し手間がかかります。そこで、Rのggridgesを使って可視化してみました。
# Jupyter notebook上でRマジックを使って実行
%%R res_logistic -w 700 -h 700 -u px -r 150
library(tidyverse)
library(ggridges)
# フォント回りの設定コードは省略しています
ggplot(data = res_logistic) +
geom_density_ridges(aes(y = career_pattern, x = 勤続年数, fill = 採用種別),
alpha = 0.6, color = "lightgray") +
scale_y_discrete(limits = rev) +
theme(
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank()
) +
scale_fill_brewer(palette = "Set2", direction = 1) +
labs(title = "キャリアパターン別の勤続年数分布(採用種別比較)")
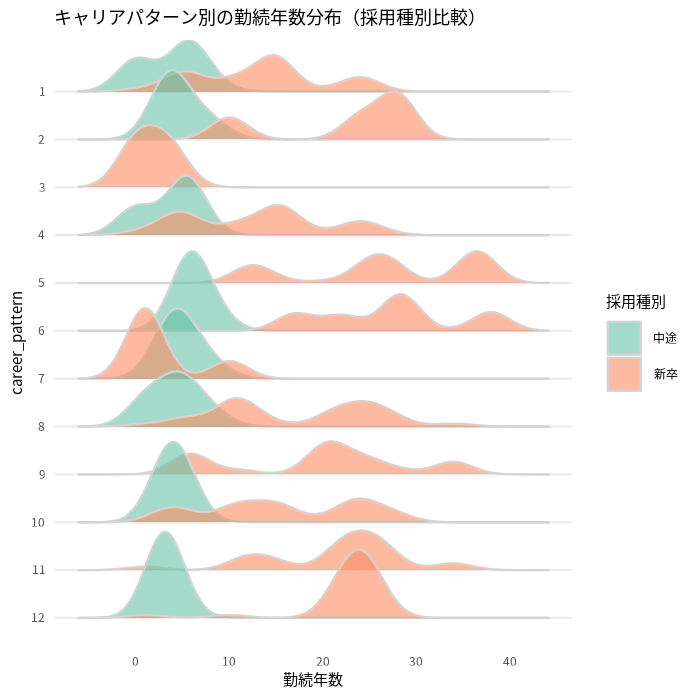
この図を見ると、勤続年数の浅い3と7の構成が異なることが分かります。特に、3は営業部の新卒だけで構成されており、キャリアの分岐が始まる前の段階だと想定されます。
5-3 経験所属の考察
最後に、各キャリアパターンに含まれる従業員が、過去にどのような所属を経験しているのかを確認します。この分析がキャリアパターンの中身を知る上で最も重要な手掛かりになります。
一方、5-1や5-2で取り上げた分析は、キャリアパターンの現在地を知るための基礎的な分析です。どちらから先に手を付けても問題ありませんが、まずは基礎的な分析から始めるのをお勧めします。
準備
分析準備のために、異動履歴データのすべてのレコードにキャリアパターンを紐づけます。キャリアパターンは従業員毎に割り当てられているので、従業員IDをキーにマージすればOKです。
th_cp = pd.merge(
th,
res_logistic.reset_index()[['従業員ID', 'career_pattern']],
on='従業員ID', how='left'
)
th_cp.head(3)
営業系キャリア
現在営業部に在籍している従業員のキャリアパターンは主に1,3,4に分かれていますが、このうち3は勤続年数の浅いパターンになります。そこで、1と4に絞って過去のキャリアを分析してみると、くっきり傾向が出てきました。
具体的には、営業活動をしている視点や課を回りながらキャリアを積み上げたパターン(4)と、マーケティングや商品企画などの専門職のキャリアに入ったパターン(1)です。新卒若手のパターンとして3があることを考えると、途中で分岐するのではないかと考えられます。
tt = th_cp.query("career_pattern in ['1', '4']")
fig, ax = plt.subplots(figsize=(6, 5))
sns.heatmap(
pd.crosstab(tt['異動後所属'], tt['career_pattern'], normalize='index')
.rename_axis('経験所属'),
cmap='Blues', robust=True, ax=ax)
ax.set_title('キャリアパターン別 過去経験(営業系)')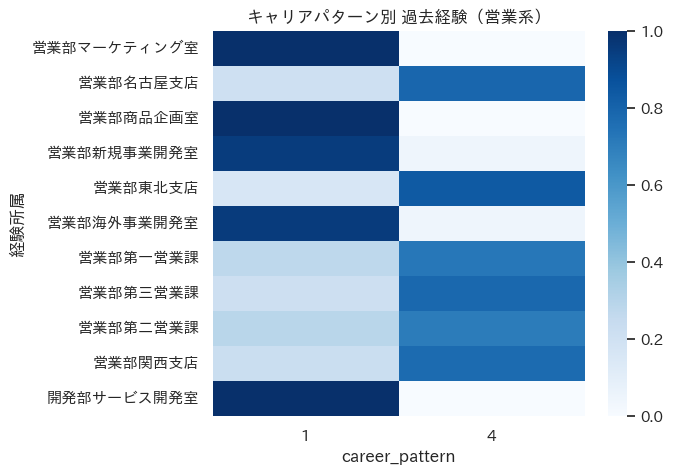
開発系キャリア
現在開発部に所属する開発系のキャリアは多くのパターンが存在しています。この内、最もボリュームが大きいのは8で、開発部内で直線的にキャリアを積み上げているパターンです。
一方、情報システム系のグループは二つに分かれており、情報システム課を中心にキャリアを作るパターン(9)と、デジタル推進室との関連があるパターン(2)があることが見て取れます。これは、DX需要の高まりを受けて情報システム課から分岐してデジタル推進室を新設したというシナリオが背景にあるのですが、これをうまく抽出できました。
また、研究部と交流のあるシニアなパターン(11)や、営業・コーポレートから移籍してきたパターン(10)の存在も見えます。
tt = th_cp.query("career_pattern in ['2','8','9','10','11']")
fig, ax = plt.subplots(figsize=(6, 8))
sns.heatmap(
pd.crosstab(tt['異動後所属'], tt['career_pattern'], normalize='index')
.rename_axis('経験所属'),
cmap='Blues', robust=True, ax=ax)
ax.set_title('キャリアパターン別 過去経験(開発系)')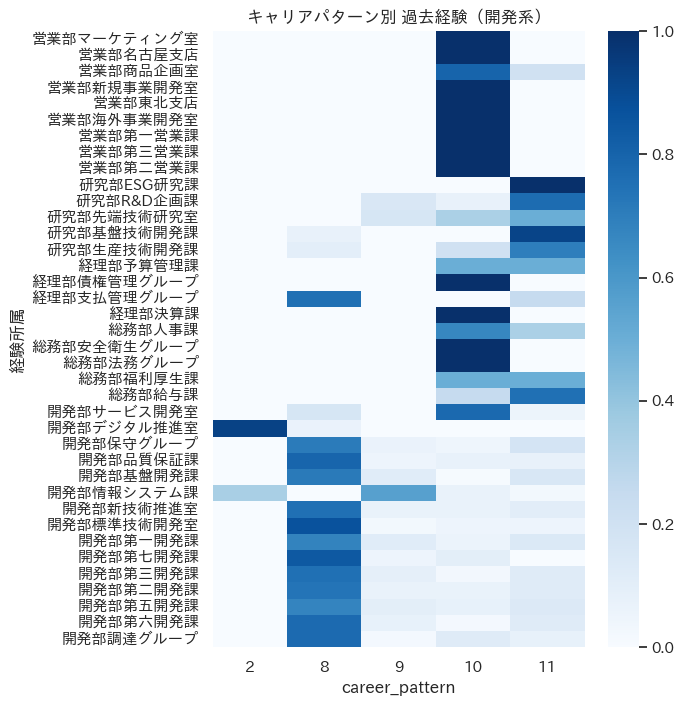
経理・総務・研究キャリア
一般にコストセンターと想定される経理・総務・研究部門は、それぞれ一つのキャリアパターンを持つことが示されています。基本的には部門内でキャリアを積み上げていく形に見えますが、これもデータの設計思想に合っています。
ただし、図をよく見ると想定よりも多くの組織との交流も見受けられました。データセットを絞ってクラスタリングをかけると、より詳細なパターンを発見できる可能性もあります。
tt = th_cp.query("career_pattern in ['5','6','12']")
tmp_mat = pd.crosstab(tt['異動後所属'], tt['career_pattern'], normalize='index')
tmp_mat = tmp_mat.rename(columns={'5':'5(経理)','6':'6(総務)','12':'12(研究)'}).rename_axis('経験所属')
fig, ax = plt.subplots(figsize=(6, 8))
sns.heatmap(tmp_mat, cmap='Blues', robust=True, ax=ax)
ax.set_title('キャリアパターン別 過去経験(経理・総務・研究)')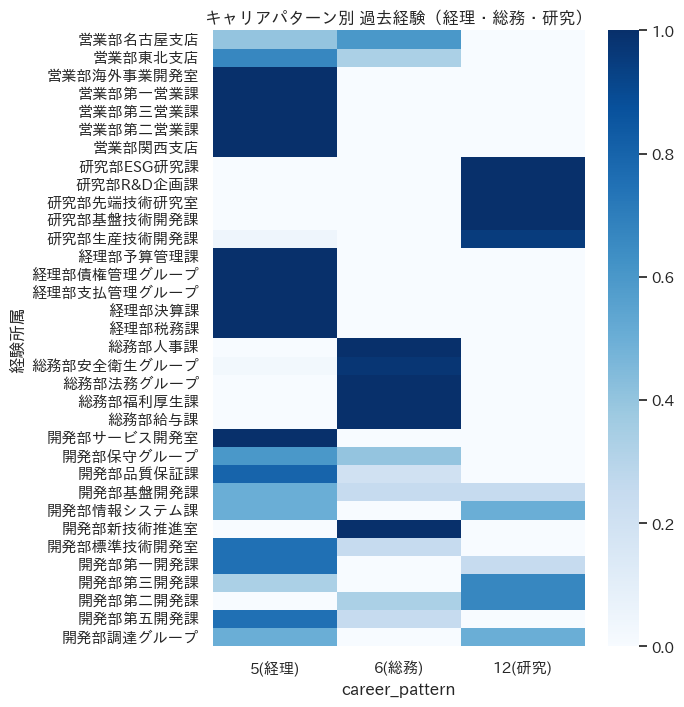
まとめ
本稿で提案したOrgPath2Vecは、異動履歴データを用いて、従業員一人ひとりのキャリアパスをベクトルとして表現する試みです。これにより、これまで個別の履歴としてしか見えにくかった異動経験を、組織全体のキャリアパターンとして俯瞰できるようになります。
もちろん、所属コードだけですべてのキャリアを理解できるわけではありません。しかし、社内にどのような経験の蓄積パターンが存在するのかを可視化することで、人事がタレントマネジメントやキャリア開発を考えるための有用なガイドになるはずです。
関連記事






