はじめまして。
「人事データ分析入門講座」講師の武田です。
このレターでは、人事データ分析に取り組み始めた方に向けて、データ分析の考え方や方法をお伝えしていきます。特に、以下の点でお困りの方の助けになりたいと思っています。
- 人事の仕事をしているが、データ分析をすることになってやり方が分からない。
- ピープルアナリティクスのプロジェクトに入っているが、データアナリストとのコミュニケーションがとりにくい。
- データ分析を独学で学んでいて、応用力を高めたい。
こうした課題感をお持ちの方に向けて基本的な技術ノウハウをお伝えしていきます。
まず1回目の配信ということで、データ分析のイメージをつかんでいただくことを目指します。
人事での分析シーンはさまざま
人事でデータを分析する場面というのはさまざまです。たとえば、エンゲージメントの課題を探ったり、ハイパフォーマーの特徴を見つけたり。
人事業務で遭遇する「実態はどうなっているのだろう?」「問題はどこにあるのかな?」「この先どうなるのだろうか?」というような疑問に対して、データを使って客観的に答えようとする場面でデータが活躍します。
もちろん、必ずしもデータだけでこうした疑問を解消できるわけではありません。データ分析は魔法ではなく、様々な制約があるからです。
しかし、データを活用することで客観性を高めることは可能です。人事データ分析に求められるのは、ファクト(データ)による客観的な裏付けであるともいえます。データを意思決定に利用するわけですね。
その一方で、データ活用の幅はもう少し広がっているとも感じています。先ほどあげた3つの疑問を振り返ってみると、
- 「実態はどうなっているのだろうか?」→現状を把握したい。
- 「問題はどこにあるのかな?」→問題を発見したい。
- 「この先どうなるのだろうか?」→将来を予測したい。
という形になります。これらの疑問や要望に対して、データから何らかのパターンや構造を抽出して着想を得ることもデータ分析の対象となります。
それでは、こうした場面に遭遇した場合に、どのようにデータを加工し、どの手法を用いて分析を進めたらよいでしょうか?
データ加工や分析の技術もまた多種多様で、何から手を付けたらよいか分からないという方もいらっしゃるかもしれません。私は10年以上前に未経験でデータサイエンティストに転身したのですが、まさにこの壁にあたってしまいました。
この壁を乗り越えるには、問題設定や分析手法や方法を身につけることも重要ですが、何より「統計的な考え方や発想法を身につける」ということが重要だったと思います。
当講座では、人事分野に特化しつつ、統計的な考え方をみなさんに身につけていただけるように進めていきます。
データと向き合う
前置きはこのくらいにして、早速データを見ることからはじめましょう。
講座で使用するデータ
当講座では私が自作した仮想の人事データを使っています。これを人事トイデータと呼びます。”トイ”というのは玩具のことで、”トイデータ”というと演習用のデータを意味します。
まずみなさんには、実際のデータを見ていただきたいと思います。以下は人事トイデータの一部を抜粋したものです。
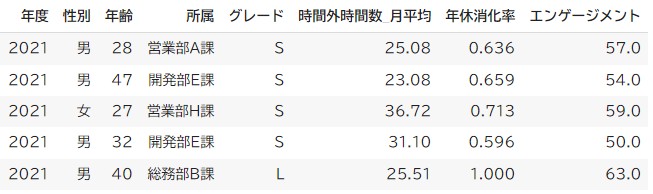
(HRトイデータ人事情報拡張版.csv)
こちらのデータは以下のページからダウンロードできます。現時点でふたつのファイルをダウンロードできるようになっていますが、当講座では「HRトイデータ人事情報拡張版.csv」を使っていきます。データの取扱いやライセンスについても下記ページをご覧ください。
人事トイデータの公開
こちらのページでは、クニラボで作成した人事トイデータを公開しています。 トイデータとは? トイデータ(Toy Data)とは、演習用に使えるリアルでないデータのことをいいます。データ分析や機械学習のライブラリに附属する場合もあり、手元にデータがなくてもそのライブラリをすぐに試せるのが利点です。 人事データ分析の演習にご活用ください ピープルアナリティクスを学んでみたいが手元に良いデータがない、という方も多いのではないでしょうか。人事データは個人情報を含むため、ピープルアナリティクスプロジェクトの正式なメンバーでないと触ることができません。 そこで、演習用にデータを自作しGoogleドライブより公開しています。これまでも代表のnote記事の中でリンクを張っていたのですが、複数の記事で利用するためこのページを作りました。 * 2023/11/29追記 「HRトイデータ_人事情報_拡張版.csv 」を追加しました。 * 2024/3/23追記 「HRトイデータ_月別時間外.csv 」を追加しました。 * 2024/11/18追記 「HRトイデータ_エンゲージメントスコア
人事データ集約にも課題
この人事トイデータは分析しやすいように集約した形になっていますが、実際のデータはこの形に加工することも大変ではないかと思います。
多くの場合、上に示したデータだけでも、①人事システムに蓄積された情報、②勤怠システムに蓄積された情報、③社内サーベイ用システムに蓄積された情報に分かれている場合もあるでしょう。
これらのデータをどうやって統合していくのか、あるいは、統合されていない状態で分析者はどのように加工すればよいのか――。このような疑問に答えるべく、データの前処理についても当講座でも扱っていきます。とはいえ、やはりデータがあるなら分析したい! と思われる方も多いと思いますので、まずは統合された人事トイデータを用いて進めていきます。
データ項目の種類(変数について)
さて、このデータは単年度のデータとなっており、それぞれの行が従業員一人のデータが記録されています。データを横に見ていくと、その従業員の基本情報や時間外の情報がわかるというわけですね。
今度はデータを縦に見ていきます。例として、年齢の列を見てみましょう。
このサンプルでは28, 47, 27, 32, 40という値が入っています。ばらばらですね。
このように、何らかのばらつきを持ったデータのことを変数といいます。そして、年齢のように数字で表されていて、足し算や引き算が可能な変量のことを「量的変数」と呼びます。
量的変数にもいくつか種類があるのですが、ひとまず量を伴う数字的なものを量的変数として見ておいてください。今回のサンプルでは、年度、時間外時間数_月平均、年休消化率、エンゲージメントも量的変数ですね。
一方、今度は性別の列を見てみてください。
このサンプルでは男, 男, 女, 男, 男となっていますね。少し偏りがありますが、やはりばらばらの値を持っているようです。しかし、この値は言葉になっているので、足し算や引き算ができません。このような変数のことを「質的変数」または「カテゴリカル変数」と呼びます。
変数の種類はデータ分析をする上で大切な概念となりますので、ぜひ覚えておいてください。








