


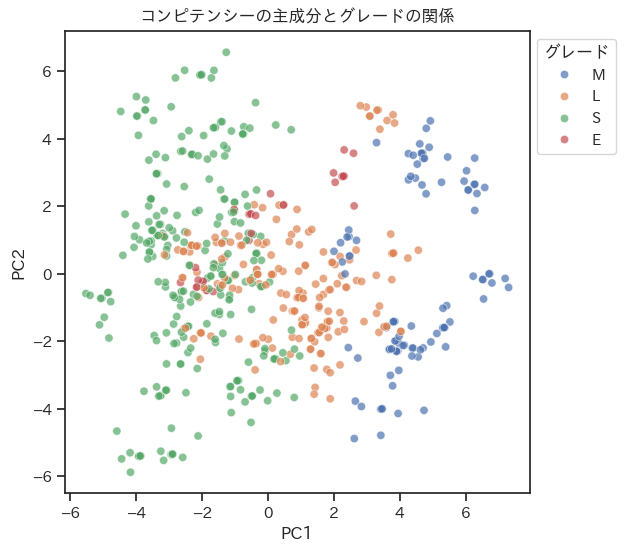
主成分分析によって次元削減された人事データに対する散布図の可視化例です。コンピテンシーなどの複数の量的変数から構成されるデータを要約する目的で、主成分分析がよく使われています。その結果を散布図を利用して可視化し、特徴をつかむことができます。
人事データ可視化の例
人事データ可視化の狙い
- 多くの変数で構成されているコンピテンシーを主成分で要約し、人事属性との関連を探る。
人事データ可視化アプローチ
利用するグラフ
- 散布図: 量的変数と量的変数の関係を可視化。
アプローチ
- データからコンピテンシーに関する項目を抽出し、主成分分析を適用する。
- 第1主成分と第2主成分を使って、データの分布を可視化する。主成分の寄与率などを確認しながら他の主成分の状況も確認する。
- グレードなどのカテゴリカル変数で色分けし、コンピテンシーとの関連を探る。
グラフの作り方
- Pythonのseaborn.scatterplotによる可視化例。
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import japanize_matplotlib
import seaborn as sns
from sklearn.decomposition import PCA
sns.set_theme(style='ticks')
plt.rcParams["figure.figsize"] = (6, 6)
japanize_matplotlib.japanize()
# データの読み込みと加工
df_hr = pd.read_csv('./HRトイデータ_人事情報_拡張版.csv')
df_hr['グレード'] = pd.Categorical(df_hr['グレード'], categories = ['M','L','S','E'])
comp = df_hr[['コンピテンシー_マネジメント',
'コンピテンシー_戦略構想力',
'コンピテンシー_対人',
'コンピテンシー_創意工夫',
'コンピテンシー_専門力',
'コンピテンシー_チームワーク',
'コンピテンシー_ストレス耐性']].copy()
# 主成分分析
pca = PCA()
ft = pca.fit_transform(comp)
res_pca = pd.DataFrame(ft,
columns=['PC{}'.format(x + 1) for x in range(len(comp.columns))])
# グラフ
fig, ax = plt.subplots()
sns.scatterplot(data=pd.concat([df_hr, res_pca], axis=1), x='PC1', y='PC2', hue='グレード', alpha=.7, ax=ax)
ax.set_title('コンピテンシーの主成分とグレードの関係')
ax.legend(loc='upper left', bbox_to_anchor=(1, 1), title='グレード')



