


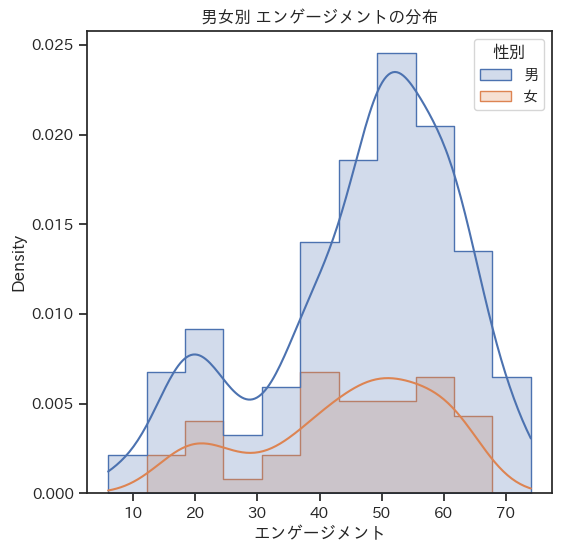
ヒストグラムを使った人事データの可視化例です。量的変数の分布を可視化できるヒストグラムに加えて、分布の密度を曲線で可視化するKDEプロットを重ねることにより、分布の形状を捉えやすくなります。
人事データ可視化の例
人事データ可視化の狙い
- 男女別のエンゲージメントの分布を比較し、課題を発見する。
人事データ可視化アプローチ
利用するグラフ
- ヒストグラム: 量的変数を階級に区切って分布を確認する。
- KDE(カーネル密度推定): 量的変数の分布を滑らかな曲線で近似して確認する。
アプローチ
- エンゲージメントに対するヒストグラムとKDEを描き、分布の特徴を確認する。
- グラフを男女別に分けて重ねて観察することで、分布の違いを観察する。
人事グラフの作り方
- Pythonのseaborn.histplotを使った可視化例。
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import japanize_matplotlib
import seaborn as sns
sns.set_theme(style="ticks")
plt.rcParams["figure.figsize"] = (6, 6)
japanize_matplotlib.japanize()
# データの読み込み
df_hr = pd.read_csv('./hr-toydata-basic-600.csv')
# グラフ
fig, ax = plt.subplots()
sns.histplot(data=df_hr, x='エンゲージメント', bins='scott', stat='density', hue='性別', kde=True, element='step', ax=ax)
ax.set_title('男女別 エンゲージメントの分布')この記事で使ったデータ
以下のページでデータを配布しています。
人事トイデータの公開
こちらのページでは、クニラボで作成した人事トイデータを公開しています。 トイデータとは? トイデータ(Toy Data)とは、演習用に使えるリアルでないデータのことをいいます。データ分析や機械学習のライブラリに附属する場合もあり、手元にデータがなくてもそのライブラリをすぐに試せるのが利点です。 人事データ分析の演習にご活用ください ピープルアナリティクスを学んでみたいが手元に良いデータがない、という方も多いのではないでしょうか。人事データは個人情報を含むため、ピープルアナリティクスプロジェクトの正式なメンバーでないと触ることができません。 そこで、演習用にデータを自作しGoogleドライブより公開しています。これまでも代表のnote記事の中でリンクを張っていたのですが、複数の記事で利用するためこのページを作りました。 * 2023/11/29追記 「HRトイデータ_人事情報_拡張版.csv 」を追加しました。 * 2024/3/23追記 「HRトイデータ_月別時間外.csv 」を追加しました。 * 2024/11/18追記 「HRトイデータ_エンゲージメントスコア





