


100%積み上げ棒グラフを使った人事データの可視化サンプルです。量的変数のカテゴリ別の内訳や割合を確認するために利用されます。
人事データ可視化の例
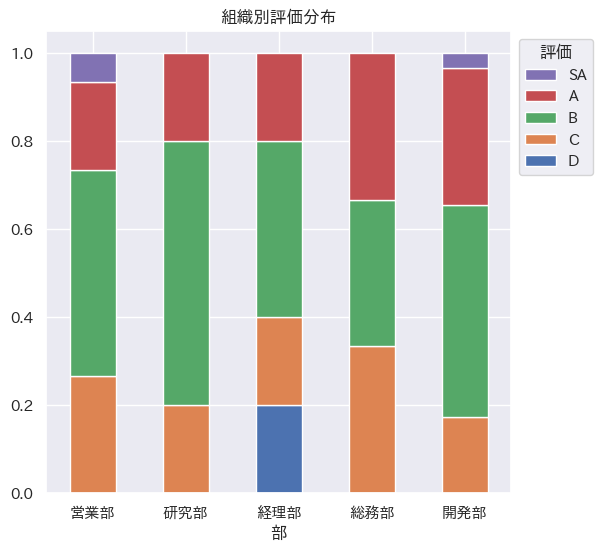
人事データ可視化の狙い
- 組織別の人事評価分布を比較し、バイアスなどを確認する。
人事データ可視化アプローチ
利用するグラフ
- 100%積み上げ棒グラフ: 層別棒グラフを他のカテゴリカル変数で分割し、各セクションの値を棒全体の合計値の割合で表すことで、各層に含まれるカテゴリカル変数の違いを比較する。
アプローチ
- 量的変数である部と成績のクロス集計を行って組織・評価別の人数を数え上げ、組織の合計人数で標準化する。(組織毎に成績別人数構成比を算出)
- クロス集計の結果を積み上げ棒グラフをして可視化し、組織別の評価分布の違いを観察する。
グラフの書き方
- Pythonのpandas.plot.barを使った可視化例。
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import japanize_matplotlib
import seaborn as sns
sns.set_theme(style='darkgrid')
japanize_matplotlib.japanize()
# データの読み込みと加工
df_hr = pd.read_csv('./HRトイデータ_人事情報_拡張版.csv')
df_hr['成績'] = pd.Categorical(df_hr['成績'], categories = ['D','C','B','A','SA'])
# グラフ
fig, ax = plt.subplots(figsize=(6,6))
pd.crosstab(df_hr['部'], df_hr['成績'], normalize='index').plot.bar(stacked=True, ax=ax)
ax.set_title('組織別評価分布')
ax.tick_params(axis="x", labelrotation=0)
# 凡例表示(見やすく)
h, l = ax.get_legend_handles_labels()
ax.legend(handles=h[::-1],labels=l[::-1], loc='upper left', bbox_to_anchor=(1, 1), title='評価')



