


Excelの上でPythonを動かせる「Python in Excel」がついに正式にリリースされました。記事を書いている2024年10月23日時点で、ビジネス向けのMicrosoft 365にて動かすことができます。個人向けはプレビュー版のままですが、試してみることもできます。
Python in Excel の概要 - Microsoft サポート
Excel の Python は、現在、バージョン 2407 (ビルド 17830.20128) 以降、Windows で現在のチャネルを実行している Enterprise ユーザーと Business ユーザーにロールアウトされています。 バージョン 2405 (ビルド 17628.20164) 以降の Windows で現在のチャネルを実行しているファミリー ユーザーと個人ユーザーはプレビュー段階で利用できます。 (2024.10.23時点の記述内容)
早速手持ちの人事トイデータを使って動かしてみたのですが、以前触ったときよりも洗練されている気がしました。ざっとご紹介したいと思います。
何ができるの?
「Python in Excel」は、その名の通りExcelシートの上でPythonを動かせる機能のことです。WindowsにPythonの動作環境がなくても、ExcelのアプリケーションだけでPythonが動くというのがうれしいポイントです。
現時点で利用できる主要なライブラリは以下の通りです。テーブルデータの分析に必要なライブラリはある程度そろっているように見えますね。その他のライブラリはこちらのページをご覧ください。
- NumPy: 数値計算や配列操作を効率的に行うためのライブラリ
- Pandas: データの操作や分析を簡便に行うためのデータフレームライブラリ
- SciPy: 科学技術計算をサポートする数学的関数や統計ツールが含まれたライブラリ
- Matplotlib: さまざまな形式のグラフや可視化を行うためのライブラリ
- Seaborn: きれいなグラフを簡単に作成できる高レベルな可視化ライブラリ
- Statsmodels: 統計モデルによる推測や統計的仮説検定を行うためのライブラリ
- Scikit-learn: 機械学習のアルゴリズムやツールが豊富に揃ったライブラリ
- NetworkX: 複雑なネットワークやグラフ構造を扱うためのライブラリ
これらのライブラリを使うことで、Excelの基本機能では実現できない分析をすることができます。これは嬉しい!
以下、人事トイデータで試してみた例をざっとあげてみます。
複雑な前処理
Python in Excelでデータ分析をするときには、Excelシート上のデータをPandasのデータフレームに取り込んで分析を進めることになります。一度データフレーム化してしまえば、グループ集計やデータ結合などPandasの機能を使うことができます。
今回は、人事トイデータに対して次ような処理をやってみました。チーム単位での管理職のコンピテンシーと他の指標との関連を探るための前処理となっています。
- 管理職のデータを抽出してコンピテンシーに関連する列に絞り込んだ上で、所属別にコンピテンシーの平均値を集計。
- 全従業員の時間外や年休、エンゲージメントなどの情報を所属別に集計。
- 上記2つの情報を結合。
- できあがったデータの一部を表示して確認。

df_mgr_comp = df.query("グレード == 'M'").filter(regex='コンピテンシー|所属', axis=1).groupby('所属').mean().reset_index()
df_team = df.filter(regex='^(?!コンピテンシー)', axis=1).groupby('所属').mean(numeric_only=True).reset_index()
df_team = pd.merge(df_team, df_mgr_comp, how='left', on='所属')
df_team.head(15)こうした前処理はデータ分析でよくやることではありますが、Excelだと手作業が入り込みやすいく、手戻りがあったときに厳しくなりがちです。Pythonだとコードが残りますので、再現しやすいメリットもあります。
データ可視化
Seabornを使うことでExcel単体では作るのが難しいグラフをスイスイ描くことができます。データ探索が捗りますね。以下の例は、当サイトのギャラリーに掲載しているグラフの一部を実装した例になります。

正式版では日本語フォントにも対応しているため、以下のようにパラメータを設定すれば日本語もきちんと表示されます。ありがたい!
import matplotlib.pyplot as plt
sns.set() # Seabornでグレー背景を使いたい場合はここで書く
plt.rcParams['font.family'] = 'Meiryo' # 日本語フォントをセットなお、Jupyternotebookでグラフを描くときに日本語フォントの問題を解決するには、japanaize_matplotlibをimportするのが通例となっていますが、本環境にはインストールされていないようです。
回帰分析
Statsmodelsを使って回帰分析をすることができます。以下の例は最小二乗法による線形回帰モデルの推測例になっています。一般的に重回帰というものですね。偏回帰係数の推測結果やp値に加え、決定係数、自由度調整済み決定係数、AICなども出力できます。

# 線形回帰による分析
import statsmodels.formula.api as smf
result = smf.ols(formula="エンゲージメント ~ 時間外時間数_月平均 + 年休消化率 + 部", data=df).fit()
print(result.summary())
# 回帰診断用のコード
## 残差のヒストグラム
sns.histplot(result.resid)
## 残差プロット
sns.scatterplot(x=result.fittedvalues, y=result.resid)
plt.xlabel('Fitted Value')
plt.ylabel('Residuals')
## QQプロット
from scipy.stats import probplot
probplot(result.resid, dist='norm', plot=plt)今回はRでよく使われるformula形式でモデルを指定してみました。モデル自体は適当な例になっていますので、ご容赦くださいませ。
回帰診断をExcel上でできるというのも嬉しいところです。上の例では残差のヒストグラム、残差プロット、QQプロットを表示しています。
機械学習(決定木の例)
Scikit-learnが動くということで、メジャーな機械学習の予測アルゴリズムはひとまず動きます。以下は決定木を使って、エンゲージメントと他の定量データの関係を解析した例になります。

from sklearn.tree import DecisionTreeRegressor, plot_tree
X = df.drop('エンゲージメント', axis=1).select_dtypes(include=['number'])
y = df['エンゲージメント']
rtree = DecisionTreeRegressor(min_samples_leaf=5, max_leaf_nodes=30, max_depth=5).fit(X, y)
plt.figure(figsize=(40, 25))
plot_tree(rtree, feature_names=X.columns, filled=True, fontsize=14)次元削減(t-SNEの例)
主成分分析、非負値行列因子分解、t-SNEなどの教師なし学習も動きます。以下はt-SNEを使って7つあるコンピテンシーの情報を2次元で要約した例になっています。データ分析の初期段階や行き詰ったときには、しばしばこうした次元削減手法に頼ることになりますので、Excelで動かせるのは便利ですね。
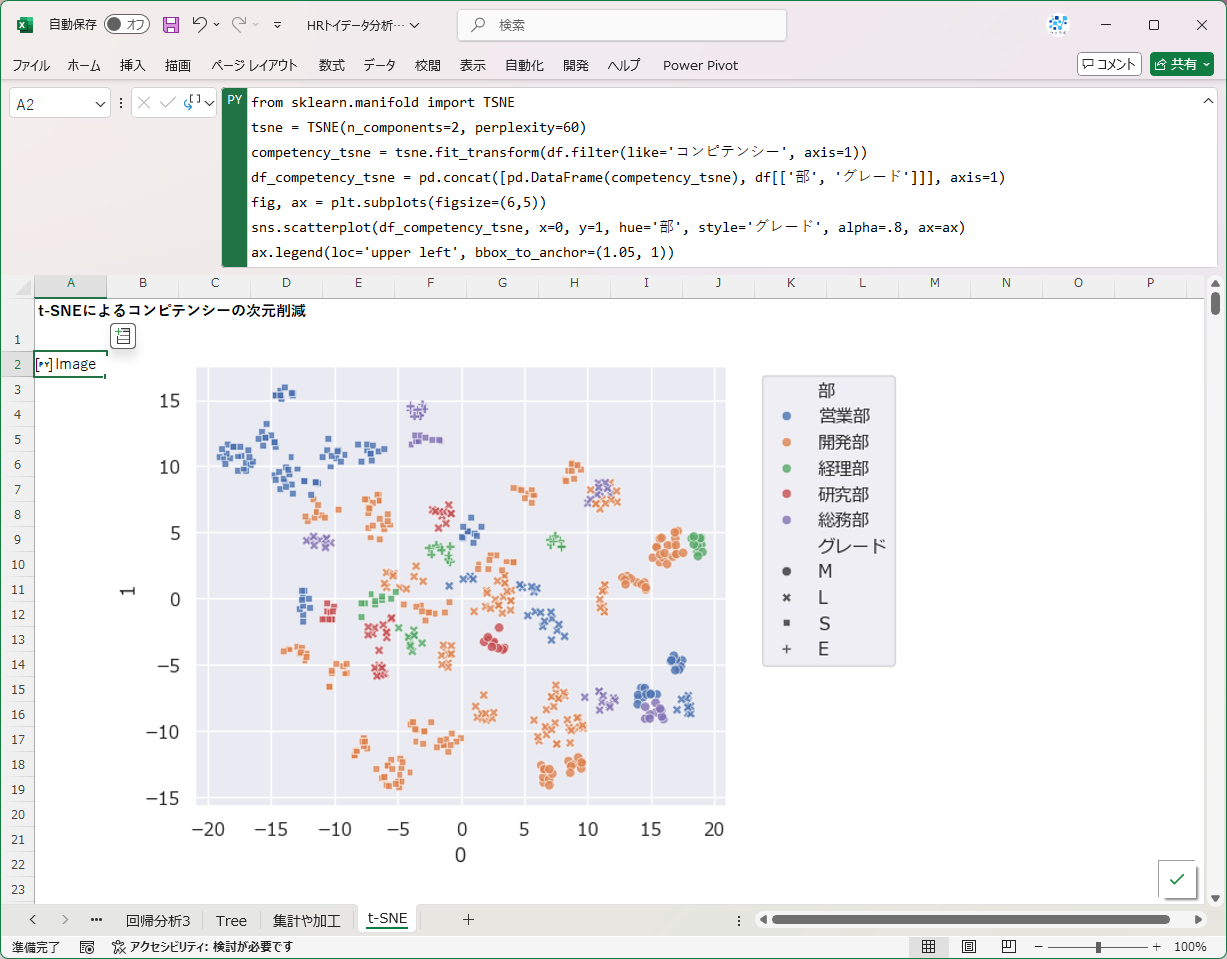
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, perplexity=60)
competency_tsne = tsne.fit_transform(df.filter(like='コンピテンシー', axis=1))
df_competency_tsne = pd.concat([pd.DataFrame(competency_tsne), df[['部', 'グレード']]], axis=1)
fig, ax = plt.subplots(figsize=(6,5))
sns.scatterplot(df_competency_tsne, x=0, y=1, hue='部', style='グレード', alpha=.8, ax=ax)
ax.legend(loc='upper left', bbox_to_anchor=(1.05, 1))どういう仕組みで動いているの?
Python in Excelを使う上で必要なのはExcelアプリのみです。ローカル環境にPythonを準備することなく動かせるというのが大きなメリットになっています。クラウド環境との接続によってこれを実現しています。
具体的には、ExcelのセルにPythonコードを書いてキックすると、Microsoftのクラウドに接続してPythonコードを実行させて結果をExcelに返す仕組みになっています。クラウド上のPython実行環境はAnacondaで構築されているようです。
クラウド上の環境は自動的に更新されるためメンテナンスフリーなのもメリット。また、セキュリティポリシーもしっかりしているようでした。詳しくは以下のリンク先の案内をご確認ください。
Excel でのデータ セキュリティと Python - Microsoft サポート
どうやったらPythonコードを使えるの?
ExcelでPythonコードを使うには、リボンメニューの「数式」→「Pythonの挿入」を選択することで、コードを入力できるようになります。この他、セルに "=py(" と入力しても同じように動作します。

Pythonコードの入力モードになると、以下のように数式バーにコードを入力することができます。入力が終わったらガイドにあるようにCtrl + Enterでコードを実行できます。また、画面右にあるようなガイドラインや例も表示されますので、活用してみましょう。
基本的な操作方法については、以下のnote記事も参考にしてみてください。
Python in Excelを試す|武田邦敬|Kunihiro TAKEDA
しばらく使っていると有料版への案内が表示される
Python in Excelは対応したMicrosoft 365のライセンスがあれば、追加料金なしで利用することができます。ところが、しばらく使っていると有料のプレミアム版への案内が表示されるようになりました。

どうやら、使っている途中でボーナス的に?プレミアム版の動作環境で実行されていたようでした。おそらく何らかの枠があるのでしょうね。このまま無料(追加費用なし)のまま使い続けることもできますが、若干動作速度が低下したように感じました。
プレミアム版になると、動作速度が速くなることに加えて、コードの実行制御を細やかにできるメリットがあるとのことです。
まとめ
今回は正式にリリースされたPython in Excelを使って、通常のExcelでは実行できない分析処理を試してみました。Pythonの実行環境を準備する必要がなく、Excelとインターネット接続環境さえあればPythonでデータ分析ができるというのは魅力的です。また、Pythonを試したい方にも嬉しい機能だと思います。




