


クロス集計とは?
2つ以上のカテゴリカル変数を組み合わせて集計した結果を表にまとめることをクロス集計といいます。例えば、所属・年代別の在籍人数を整理したり、組織サーベイで選択式の質問項目の回答結果を整理したりする場合に利用します。
このようにしてできあがった表のことをクロス集計表または分割表といいます。
分割表というと、基本的にはカテゴリカル変数の組み合わせが出現する頻度や割合を集計し、表としてまとめたものを指します。
一方、クロス集計表は頻度集計の他に、カテゴリカル変数の組み合わせ条件の下で別の量的変数の統計量を整理したピボットテーブルを指すこともあります。
どのような場面で利用するの?
クロス集計は次のような場面で利用します。
- カテゴリカル変数の組み合わせでデータ件数を数え上げたいとき。
- カテゴリカル変数の組み合わせたグループの大きさや割合を比較したいとき。
- 2つのカテゴリカル変数の統計的な関係を考察したいとき。
- カテゴリカル変数でグループ化したデータの特徴量を作る時。
Pythonでクロス集計表を作る
Pythonでグループ集計をする場合、pandasを使うと便利です。pandasはメモリ上にテーブルデータを取り込んで様々な演算や分析を行えるライブラリで、データ分析者がよく利用しています。
まずは、当サイトで提供している人事トイデータ(拡張版)をpandasのデータフレームに取り込んでみます。
import pandas as pd
# データをpandasのデータフレームに読み込む
df_hr = pd.read_csv('./hr-toydata-basic-600.csv')
# カテゴリカル変数列に絞ってデータフレームの先頭10行を表示する
df_hr.select_dtypes(include = object).head(10)
crosstab()を使った集計
手始めに部と性別の出現頻度を調べるためにクロス集計をしてみました。部によって随分様子が異なることがわかります。
pd.crosstab(df_hr['部'], df_hr['性別'], margins=True)
部毎の在籍人数が異なるので度数を見るよりも割合で確認したいですね。クロス集計表で割合を見る場合、行に対する割合を見る方法と列に対する割合を見る方法があります。今回は、男性と女性の比率に関心があるので行に対する割合を見てみます。
pd.crosstab(df_hr['部'], df_hr['性別'], margins=True, normalize='index').round(2)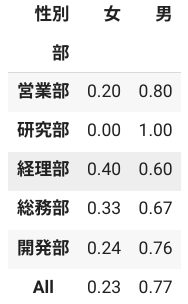
こちらの表をみることで、女性比率が比較的多い部とそうでない部があることがわかりました。
pivot_table()を使った集計
crosstabの他に、pivot_tableを使ってクロス集計することも可能です。以下は年代およびグレード別の在籍人数を集計した表になります。
# グレードの順番を定義する
df_hr['グレード'] = pd.Categorical(df_hr['グレード'], categories = ['E','S','L','M'])
pd.pivot_table(df_hr, index='年代', columns='グレード', values='従業員ID', aggfunc='count', margins=True)
# crosstabを使う場合のコード
# pd.crosstab(df_hr['年代'], df_hr['グレード'], margins=True)
出現頻度を集計するだけならcrosstabを使う方が簡素に書けます。一方、2つのカテゴリカル変数の組み合わせ条件に対して、他の量的変数の統計量を計算したい場合は、pivot_table()が適しています。例えば、以下の例は年代・グレード別に平均時間外を計算した例です。
pd.pivot_table(df_hr, index='年代', columns='グレード', values='時間外時間数_月平均', aggfunc='median', margins=True).round(2)
行パーセントと列パーセント
データの出現頻度に関するクロス集計を作るとき、セルごとの出現割合を計算することもあるでしょう。このとき、行に対する割合を計算する方法(行パーセント)と、列に対する割合を計算する方法(列パーセント)があります。どちらの計算方法を選択するかは、分析の目的によってかわってきます。
内訳として解釈する場合
ひとつの指針は、「何の内訳を見たいのか?」という観点です。例として、冒頭に出した部別の男女比率について取り上げてみましょう。以下、左側の表は行パーセント、右側は列パーセントで割合を計算したのクロス集計表です。
# 行パーセント
row_ratio = pd.crosstab(df_hr['部'], df_hr['性別'], margins=True, normalize='index').round(2)
# 列パーセント
col_ratio = pd.crosstab(df_hr['部'], df_hr['性別'], margins=True, normalize='columns').round(2)
女性比率に着目してみると、行パーセントで見た場合は経理部の比率がもっとも大きく、列パーセントで見た場合は開発部がもっとも大きくなりました。これはどのように考えるべきでしょうか?
まず行パーセントの方は、部の在籍人数に着目して男女の内訳を見ている形になっています。この例でいうと、組織単位の女性比率が人事上のKPIになっているような場合は、こちらの表で確認するのが適しています。
一方、列パーセントの方は、従業員(人)に着目し、組織全体での配置傾向を確認することができます。具体的には、'All'列の割合が従業員の配置傾向を示し、それに対して男女で配置傾向の違いを確認することもできるでしょう。
より具体的に議論するために、男女比率を念頭においた配置施策の課題を検討する場面を想像してみます。
仮に、一斉採用で採用後に配置が決まり、かつ、部をまたぐ人事異動がない会社であったとします。この場合、列パーセントの表を見ると、女性は経理部と総務部に配置されやすい傾向にありますが、開発部への配置は性別で大きな差はなさそうだとも読み取れます。
一方、各部で採用プロセスを回しているような場合は、行パーセントの表を参考にする方がよさそうです。
現実的には採用の意思決定は人事と各所属の両面が絡む場合もあるでしょうから、両方の観点で見るべきかもしれません。
なお、Jupyter Notebookで表を横並びで表示するにはひと工夫必要です。以下、参考コードを掲載します。(こちらの記事を参考にさせていただきました)
# Jupyter notebookで表を横並びに表示させるための処理
def display_tables(df1, df2, name1='', name2=''):
class Disp:
def _repr_html_(self):
html_ = ''
for d, n in zip([df1, df2], [name1, name2]):
html_ += d._repr_html_().replace(
'<div>', '<div style="float: left; padding:20px;">' + n)
return html_
return Disp()
display_tables(row_ratio, col_ratio, '行パーセント', '列パーセント')目的変数・説明変数として解釈する場合
2つのカテゴリカル変数があったとき、片方の変数がもう片方に影響を与える影響を考察したい場面もあるでしょう。ここでは、回帰問題になぞらえて影響を与えている変数を説明変数、影響を受ける変数を目的変数と想定してみます。
この問題を頻度に基づくクロス集計表を用いて考察する場合は、説明変数に対する目的変数の内訳を見て考察するアプローチをとります。つまり、目的変数を横軸(表頭)に、説明変数を縦軸(表側)に取るのであれば、行パーセントを見ることになります。
具体的な例として、学歴とパフォーマンスの関係を見てみましょう。パフォーマンスの定義は様々で議論が尽きない話題ですが、今回はひとまず上位の成績を取っているひとをハイパフォーマーと見立てて集計してみました。
# ハイパフォーマーの特徴量を作る(例示用)
df_hr['HP'] = 'ハイパフォーマーでない'
df_hr['HP'].mask((df_hr['成績'] == 'SA') | (df_hr['成績'] == 'A') , 'ハイパフォーマーである', inplace=True)さて、ここでの関心事は学歴と当社でのパフォーマンスに関連があるか否かという点です。学歴・パフォーマンスともにカテゴリカル変数ですので、相関係数による解析ができません。そこで、クロス集計表で関連性を探ってみることにします。
目的変数をハイパフォーマーであるか否かを示すHP、説明変数を最終学歴とし、出現頻度を計算すると以下のようになりました。
pd.crosstab(df_hr['最終学歴'], df_hr['HP'], margins=True)
目的変数が表頭に来ていますので、先ほどの指針に従えば行パーセントを取ることになります。以下の表を見ると、ハイパフォーマーの割合は修士・学士ともに近接していて、大きな差があるとはいえません。つまり、今回のデータでは、最終学歴とパフォーマンスの関連はなさそうだと考察できます。
pd.crosstab(df_hr['最終学歴'], df_hr['HP'], margins=True, normalize='index').round(2)
注意点
ちなみに、今回のデータに対して列パーセントを取るとどのようになるでしょう?
以下に列パーセントを取った表を掲載します。
pd.crosstab(df_hr['最終学歴'], df_hr['HP'], margins=True, normalize='columns').round(2)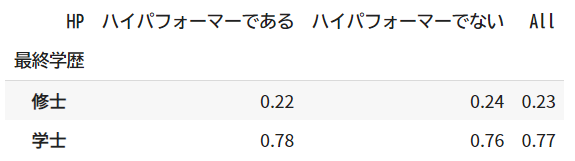
こちらの表ですが、もしセルの値だけに着目すると学士×ハイパフォーマーのセルがもっと割合が大きくなり、ミスリードしそうですね。ただし、表を注意深く読めば、全体の学士・修士の割合と大差ないことが分かります。
今回のケースで問題となるのは、「ハイパフォーマー」のみのデータで解析した場合でしょう。もし、手元にあるデータがハイパフォーマーのものだけだったとすると、ハイパフォーマーの中で学士と修士の割合を出して考察してしまうかもしれません。そうなると、上の表でハイパフォーマーの列の情報だけで考察することになってしまいます。
データ分析の基本は比較による分析です。今回のように「ポジティブなケース」だけを見ても実はよくわかりません。仮に、ポジティブなケースに共通点が発見されたとしても、それがネガティブなケースには存在しない特徴だとはいい切れないからです。




