


グループ集計とは?
データを何らかのグループに分割し、グループ別に集計をして値を求めることをグループ集計といいます。例えば、従業員の時間外時間数のデータがあったとき、組織別の平均を出して比較するような場面でグループ集計を使います。
具体的には、グループ集計を使って以下のような値を求めます。
- データ件数: データの数(カウント・数え上げ)
- 平均値: すべてのデータを足してデータ件数で割った値(算術平均)
- 中央値: データを小さい順に並べたときにちょうど中央にくる値
- 最頻値: もっとも多く出現する値
- 最大値: データの中で最も大きな値
- 最小値: データの中で最も小さな値
- 分散: 平均値と各データの差を2乗した値を使ってデータのばらつきを表した値
- 標準偏差: 分散の平方根をとって元のデータの単位でばらつきを表した値
どのような場面で利用するの?
グループ集計は以下のような場面で利用します。
- 量的変数の外観を把握するとき。
- 量的変数の外れ値を確認するとき。
- グループ別に量的変数の統計量を比較するとき。
- 回帰モデルや分類モデルで新しい特徴量(共変量)を作るとき。
- ダッシュボード作りなどデータ可視化のための準備をするとき。
Pythonでグループ集計をする
Pythonでグループ集計をする方法はいくつかありますが、データ分析の場面ではpandasを使うと便利です。pandasはメモリ上にテーブルデータを取り込んで様々な演算や分析を行えるライブラリで、データ分析者がよく利用しています。
まずは、当サイトで提供している人事トイデータ(拡張版)をpandasのデータフレームに取り込んでみます。
import pandas as pd
# データをpandasのデータフレームに読み込む
df_hr = pd.read_csv('./hr-toydata-basic-600.csv')
# データフレームの先頭10行を表示する
df_hr.head(10)
データの様子を確認するため、データの件数と項目数を確認したうえで、従業員の数と年度をざっと確認してみましょう。単年度のデータで、かつ、データ件数と従業員数が一致していることが確認できました。
print(f"行数・列数: {df_hr.shape}")
print(f"従業員数 : {df_hr['従業員ID'].nunique()}")
print(f"年度 : {df_hr['年度'].unique()}")〈出力結果〉
行数・列数: (600, 26)
従業員数 : 600
年度 : [2021]
続いて、時間外勤務の状況を把握するため、「時間外時間数_月平均」の基本統計量を確認してみましょう。全社の平均時間外は34時間であることがわかりました。
df_hr['時間外時間数_月平均'].describe()〈出力結果〉
count 600.000000
mean 34.051583
std 16.006480
min 0.000000
25% 23.432500
50% 30.730000
75% 41.342500
max 88.150000
Name: 時間外時間数_月平均, dtype: float64
groupby()を使った集計
それでは、所属によって時間外に違いがあるのか確認してみましょう。グループ集計で、部別の平均時間外を算出してみます。pandasのデータフレームで利用できるgroupby()を使って平均を比較すると、研究部の時間外が突出していることがわかります。
df_hr.groupby('部')['時間外時間数_月平均'].mean()〈出力結果〉
部
営業部 24.230400
研究部 59.317600
経理部 34.274600
総務部 22.230500
開発部 37.182586
Name: 時間外時間数_月平均, dtype: float64
groupby()は一度に複数の統計量を計算することもできます。時間外と年休消化率に対して複数の統計量を見てみるとこのようになりました。
df_hr.groupby('部')[['時間外時間数_月平均', '年休消化率']].agg(['mean', 'std', 'max', 'min'])
複数のキー項目で集計することも可能です。次の例は、部と課を集計の単位とし、コンピテンシーの平均を算出した結果です。
df_hr.groupby(['部', '課']).mean(numeric_only=True).filter(like='コンピテンシー', axis=1).round(2)
pivot_table()を使った集計
複雑なグループ集計を行う場合はpivot_table()を使うとわかりやすいです。例えば、部および年代別の時間外時間数・年休消化率の平均を見るときに、行に部、列に年代をとったマトリックスで整理したいとします。このようなとき、pivot_table()を利用します。
df_div_overtime = pd.pivot_table(df_hr, index='部', columns='年代', values=['時間外時間数_月平均', '年休消化率'], aggfunc='mean').round(2)
df_div_overtime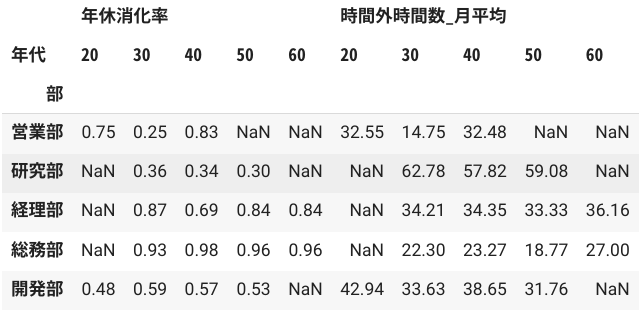
横持ちデータと縦持ちデータ
上の表は人の目で全体を俯瞰するにはとても見やすく、一般的に「横持ちデータ」といいます。一方、統計ソフトウェアでグラフを描いたり、統計モデルを適用したりするうえでは扱いにくい場合もあります。このような場合は、pandasのstack()を用いて「縦持ちデータ」に整形することができます。
df_div_overtime_long = pd.DataFrame(df_div_overtime.stack().reset_index())
df_div_overtime_long.columns = ['部', '年代', '年休消化率', '時間外時間数_月平均']
df_div_overtime_long
このような縦持ちデータは人が見るにはわかりにくいのですが、機械処理しやすいデータ形式になっています。例えばこちらのデータを使って、部および年代別の時間外と年休消化の関係を分析することも可能です。
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
fig, ax = plt.subplots(figsize=(7,7))
sns.scatterplot(data=df_div_overtime_long, x='時間外時間数_月平均', y='年休消化率', hue='年代', style='部', s=100, ax=ax)
ax.set_title('部・年代別 時間外と年休消化率の関係')
ax.set_xlabel('平均時間外時間数')
ax.set_ylabel('平均年休消化率')




