


箱ひげ図とは?
箱ひげ図は量的変数のばらつきを視覚的に表すことができるグラフで、中央値を中心にデータがどのように分布しているか一目で確認することができます。
ひとつの量的変数に対して箱ひげ図を作ることもできますが、別の質的変数でグループを作ってグループ同士でばらつきを比較するときによく使います。中央値、四分位数といった統計量を用いて描写するため、データ量が多くても素早く描写することができます。

箱ひげ図の見方
箱ひげ図は、量的変数に対する統計量である四分位数を線と箱で描写したものです。
具体的には、データを小さい順に並べて四等分し、その境界にあるデータ点を統計量としてとらえて作図していきます。
- 最小値
- 25%点(第1四分位数)
- 中央値(第2四分位数)
- 75%点(第3四分位数)
- 最大値
このうち、25%点から75%点に含まれるデータ範囲を四分位範囲といい、中央値を中心に全体の半分のデータが収まる範囲となります。箱ひげ図では四分位範囲を四角い箱で描写します。また、最小値から25%点、75%点から最大値までの間は線で表現され、「ひげ」と呼ばれます。以下のグラフでは、実際のデータと箱ひげ図を並べてみましたので見比べてください。

このように、箱ひげ図を用いてデータの範囲を視覚的に見ることで、データのばらつきを分かりやすく捉えることができます。
基本的に箱ひげ図は四分位数を元に作られますが、極端な値を外れ値として分けて表示することができます。上のグラフでも、表示下限を下回ったデータが外れ値として点で表現されているのが分かるかと思います。もし外れ値がなければ、上の箱ひげ図の表示下限は最小値になります。
それでは、何をもって外れ値と判断されるのでしょうか?
今回の作図では、「ひげ」の長さが四分位範囲の1.5倍を超える場合に外れ値と判定されるように設定しています。この閾値は変えることもできますし、外れ値自体の描写を行わないことも可能です。
Pythonで箱ひげ図を描く
この記事で掲載している箱ひげ図は、当サイトで提供している人事トイデータ(拡張版)を使用したものです。また、ツールとしてPythonのSeabornを用いて作図しました。具体的なPythonコードは以下のようになります。
まずは初期設定とデータの読み込みから。
# ライブラリの読み込みと初期設定
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set()
plt.rcParams["figure.figsize"] = (5, 5)
japanize_matplotlib.japanize()
# データの読み込み
df_hr = pd.read_csv('./hr-toydata-basic-600.csv')データが読み込めたのでデータサンプルを確認します。データから採用種別とエンゲージメントを取り出して、先頭10行を表示してみました。
df_hr[['エンゲージメント','採用種別']].head(10)
次に、冒頭に示した散布図を描いてみましょう。今回は採用種別毎にエンゲージメントの分布を可視化してみます。
sns.boxplot(data=df_hr, x='採用種別', y='エンゲージメント')
xとyの項目指定を変えることで、横向きの箱ひげ図を作ることもできます。比較するグループの名称が長い場合は、横向きにすると読みやすくなります。
sns.boxplot(data=df_hr, x='エンゲージメント', y='採用種別')
四分位数だけでなく平均値も合わせてみることもできます。以下の箱ひげ図では、緑色の▲印の箇所が平均値を表しています。中央値と平均値を比較することで、分布の歪みを把握できます。
sns.boxplot(data=df_hr, x='採用種別', y='エンゲージメント', showmeans=True, color='w')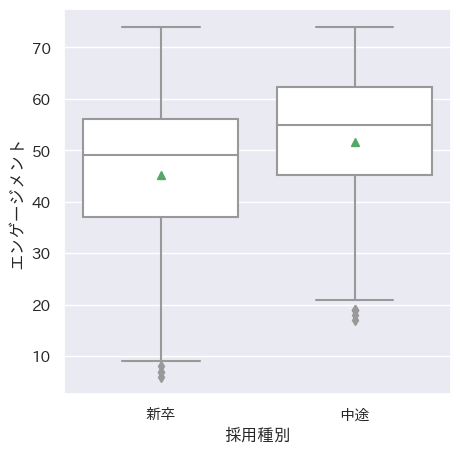
箱ひげ図を細分化する
ここまでは箱ひげ図を使ってグループ別の分布を見てきました。このグループ分けを更に細分化することもできます。試しに、上にあげた箱ひげ図を性別で細分化してみましょう。seabornでは'hue'オプションを指定することで細分化できます。
sns.boxplot(data=df_hr, x='採用種別', y='エンゲージメント', hue='性別')
上の例では採用種別→性別と細分化しましたが、性別→採用種別という形で細分化することも可能です。どちらを使うかは、分析のテーマによって変わってくるでしょう。
sns.boxplot(data=df_hr, hue='採用種別', y='エンゲージメント', x='性別')
箱ひげ図を使うときの注意点
箱ひげ図を使うと手早く分布を比較できるので大変便利ですが、以下の点に注意しなくてはなりません。
- 視覚的に箱の中にほとんどの点が存在しているように感じるが、必ずしもそうではない。
- 必ずしも中央値付近にデータが密集しているとは限らない。
分かりやすい例として、人事トイデータの中から時間外時間数の箱ひげ図を見てみます。以下の箱ひげ図は、年代別に時間外時間数の分布を可視化したグラフです。
sns.boxplot(data=df_hr, x='年代', y='時間外時間数_月平均', color='w')
上の箱ひげ図をみると、年代ごとにばらつきは違っているようですが、中央値で見ると30時間付近を中心に時間外が分布しているように見えるかもしれません。
しかし本当にそうでしょうか?
これを確かめるために、データ点の分布を具体的にたしかめることができるストリッププロットを使ってみましょう。
データ点の分布を観察できるストリッププロット
ストリッププロットは、データのグループ別に量的変数の分布を点で可視化することができます。箱ひげ図とは違って点をそのままプロットできるので実態をつかみやすくなります。ただし、一直線上に点を並べると重なって見えないので、点の重なりがわかるように質的変数の軸に対してランダムノイズが付与されています。
先ほど箱ひげ図で見た年代別時間外時間数をストリッププロットで見てみましょう。
sns.stripplot(data=df_hr, x='年代', y='時間外時間数_月平均',alpha=.7)
ストリッププロットで見ると、箱ひげ図で見た場合と異なる印象をうけますね。年代によってはクラスターが複数存在しているように見えますし、思ったほど中央値付近に固まっているわけでもない印象です。このように、箱ひげ図に加えてストリッププロットを併用するとミスリードを防ぐことができます。
ストリッププロットを細分化する
ストリッププロットのグループ分けを細分化したい場合は、'hue'オプションで指定します。ただし、標準では色分けがされるだけで同じ個所にプロットされます。これでも同じような分布をしているグループと、そうでないグループの見分けはつきますね。
sns.stripplot(data=df_hr, x='年代', y='時間外時間数_月平均', hue='性別', alpha=.7)
箱ひげ図と同じように、ストリッププロットで明確に領域を分けて細分化する場合は、'hue'オプションに加えて、'dodge'オプションを設定します。
sns.stripplot(data=df_hr, x='年代', y='時間外時間数_月平均', hue='性別', alpha=.7, dodge=True)
ストリッププロットと箱ひげ図を重ねる
箱ひげ図とストリッププロットを併用する上で、重ねてみるという方法も有効です。
fig, ax = plt.subplots()
sns.boxplot(data=df_hr, x='年代', y='時間外時間数_月平均', color='w', ax=ax)
sns.stripplot(data=df_hr, x='年代', y='時間外時間数_月平均',alpha=.7, ax=ax)
ストリッププロットに中央値や平均値を追加する
ストリッププロットに箱ひげ図を重ねると見えにくいという場合は、代表値である中央値と平均値だけを重ねると分かりやすくなります。以下のグラフでは、中央値が黒色の実線で、平均値が緑色の破線で表現されています。
fig, ax = plt.subplots()
sns.stripplot(data=df_hr, x='年代', y='時間外時間数_月平均', alpha=.7, ax=ax)
sns.boxplot(data=df_hr, x='年代', y='時間外時間数_月平均', ax=ax,
showmeans=True, meanline=True,
whiskerprops={'visible': False},
showfliers=False, showbox=False, showcaps=False)
この記事で使ったデータ
以下のページでデータを配布しています。





